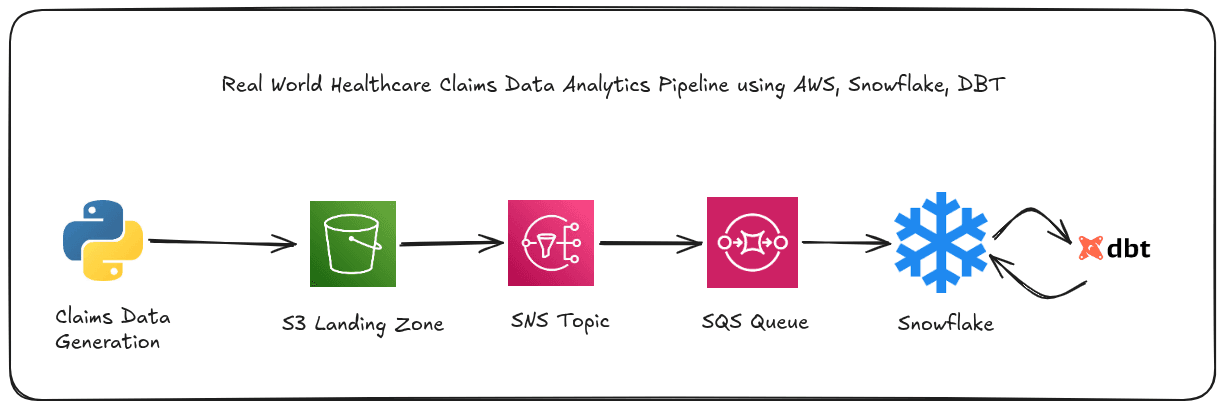
Part 1 of 2: This post covers building the foundational data pipeline for a healthcare claims analytics project called claims-pulse. We walk through realistic data generation, uploading to S3 using boto3, wiring AWS SNS and SQS to trigger Snowpipe for automatic ingestion into Snowflake, and using dbt to transform raw claims data into business-ready analytics marts. Data quality checks run at two separate layers: before S3 using Great Expectations, and after transformation using dbt tests. Part 2 will cover orchestrating this entire pipeline with Apache Airflow.
Why I built this?
I am a data engineer working in the US healthcare domain. My day-to-day involves claims and appeals data from EDI 835 and 837 files, the standard electronic formats payers and providers use to exchange billing information. Healthcare is one of the most data-intensive industries in the world. The US processes over 1.2 billion claims annually across thousands of payers, providers, and health plans.
Behind every one of those claims is a chain of systems: electronic health records, practice management software, clearinghouses, and payers — each one a potential source of data quality problems.
In my experience, the hardest problems in healthcare data engineering are not technical. These are data quality problems:
A provider submits a claim without a diagnosis code
A payment system processes a refund before the original service date
A billing error causes a paid amount to exceed the billed amount
These are not edge cases. They happen daily, at scale.
I built claims-pulse to simulate this reality and demonstrate how a modern data stack (AWS S3, Snowflake, and dbt) can handle the full journey from noisy raw data to reliable business analytics.
Architecture Overview

The pipeline moves data through five stages:
A Python script generates realistic claims data with intentional defects
Great Expectations validates the data before it reaches S3
Files land in S3, which triggers an SNS event notification
SNS delivers the event to SQS, where Snowpipe picks it up and loads the data into Snowflake
DBT models transform raw Snowflake tables into staging views, intermediate joins, and business-ready mart tables
Technology Stack
| Layer |
Tool |
| Data Generation |
Python + Faker |
| Pre-upload Validation |
Great Expectations |
| Data Storage |
AWS S3 |
| Event Notification |
AWS SNS |
| Message Queue |
AWS SQS |
| Data Warehouse + Ingestion |
Snowflake + Snowpipe |
| Transformation |
dbt (dbt-snowflake adapter) |
| Orchestration (Part 2) |
Apache Airflow |
Implementation
1. AWS & Snowflake Configuration
Before writing any pipeline code, you need to wire up the infrastructure. These are one-time setup steps. Once done, you add the resulting credentials and ARNs to your .env file and the pipeline handles the rest automatically.
Here is the full setup sequence:
Step 1: Create the S3 Bucket
S3 is the entry point for all data in this pipeline. Every raw claims file lands here first before anything downstream touches it. Think of S3 as the physical inbox on your desk — everything comes in through it, and nothing gets processed until it arrives.
In the AWS Console, go to S3 → Create Bucket and configure:
Bucket name: Must be globally unique across all AWS accounts
Region: us-east-1 (match your Snowflake deployment region to avoid cross-region data transfer costs)
Versioning: Enable — this lets you recover files that were accidentally overwritten
Default encryption: SSE-S3 (server-side encryption at rest, no extra cost)
Block all public access: Keep enabled ✅

Once created, set up this folder structure inside the bucket. You can do this manually in the console, or let the upload script create it on first run:
your_s3_bucket/
└── claims_dw/
└── raw/
├── claims/
├── patients/
├── providers/
└── claim_line_items/
Each table gets its own folder. This matters because each Snowpipe pipe watches a specific S3 prefix, if they all shared one folder, you would have no clean way to route files to the right table.

Step 2: Create the SNS Topic
AWS SNS (Simple Notification Service) is a publish/subscribe messaging service. A publisher sends one message to a topic, and SNS delivers a copy of that message to every subscriber.
In this pipeline, SNS sits between S3 and SQS. When a new file lands in S3, S3 sends an event to the SNS topic, which forwards it to the SQS queue, which Snowpipe reads.
Why add SNS at all? Why not have S3 send events directly to SQS?
The answer is extensibility. S3 can only send event notifications to a fixed list of destinations per bucket configuration. If you wire S3 directly to SQS and later want to also send those same events to a Lambda function or another SQS queue, you have to modify the S3 bucket configuration each time. With SNS in the middle, you just add a new subscriber to the existing topic — S3 configuration stays untouched. This is the fan-out pattern, and it is standard practice in production event-driven pipelines.
In the AWS Console, go to SNS → Create Topic:
Copy the SNS Topic ARN as it is used in the next steps.

Now configure S3 to send events to this topic. Go to S3 → your bucket → Properties → Event Notifications → Create Event Notification:
Event name: claims-uploaded
Events: s3:ObjectCreated:* (fires on any file creation — Put, Post, Copy, multipart upload)
Prefix: claims_dw/raw/ (only files under this path trigger notifications)
Destination: SNS Topic → claims-pulse-s3-events

Step 3: Create the SQS queue
AWS SQS (Simple Queue Service) is a message queue. Producers drop messages in; consumers pull messages out. The queue holds messages durably until a consumer explicitly deletes them after successful processing.
In this pipeline, SQS acts as a buffer between SNS (which fires the instant S3 receives a file) and Snowpipe (which polls for new messages on its own schedule).
Why is this buffer important?
Without SQS, if Snowpipe were unavailable at the exact moment S3 fired an event, that notification would be lost permanently. SQS stores messages for up to 14 days, so Snowpipe can restart, recover, and process all queued events without any data loss.
In the AWS Console, go to SQS → Create Queue:
Name: claims-pulse-snowpipe-queue
Type: Standard
Visibility timeout: 30 seconds — prevents duplicate processing by hiding a message from other consumers while one consumer is working on it
Message retention: 14 days — enough time to debug failures and replay messages
Dead Letter Queue: Create a companion claims-pulse-snowpipe-dlq queue. Set Maximum receives = 3 — messages that fail processing 3 times get moved to the DLQ instead of blocking the main queue indefinitely

Now subscribe this SQS queue to the SNS topic. In the SQS console, navigate to the SNS Subscriptions tab and click Subscribe to Amazon SNS topic. Enter the ARN of the claims-pulse-s3-events topic you created in Step 2.

Test the flow before moving on. Drop any file into claims_dw/raw/claims/ in S3, then go to the SQS console, select claims-pulse-snowpipe-queue, and click Send and receive messages → Poll for messages. You should see a message appear within seconds confirming the event traveled the full S3 → SNS → SQS path.
You can also confirm from the monitoring tab that messages are flowing through.

Here is what the message Snowpipe actually reads looks like:
{
"Records": [{
"eventName": "ObjectCreated:Put",
"s3": {
"bucket": { "name": "your-bucket" },
"object": { "key": "claims_dw/raw/claims/claims.csv" }
}
}]
}
Snowpipe reads this message, extracts the S3 key, and executes COPY INTO claims_db.raw.claims FROM @stage/claims/. Once the data is loaded successfully, Snowpipe deletes the message from SQS. If loading fails, the message stays in the queue for retry — up to 3 attempts before the DLQ catches it.
Step 4: Create IAM Role for Snowflake
Snowflake needs read access to your S3 bucket and read access to your SQS queue. The secure way to grant this is through an IAM Role with a trust relationship, not through hardcoded IAM user credentials.
Important: Never embed AWS access keys directly in SQL statements or configuration files that get committed to version control. Use IAM roles with trust relationships. The example below shows the correct approach.
In the AWS Console, go to IAM → Roles → Create Role:
Attach this inline policy to the role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::claims-pulse-landing",
"arn:aws:s3:::claims-pulse-landing/*"
]
},
{
"Effect": "Allow",
"Action": [
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes"
],
"Resource": [
"arn:aws:sqs:us-east-1:YOUR_ACCOUNT_ID:snowpipe-*-queue"
]
}
]
}
Notice the SQS Resource uses a wildcard (claims-pulse-*) to cover both the main queue and the DLQ without listing each ARN separately.
With the AWS infrastructure in place, you now set up Snowflake to receive and store the data. This involves creating the warehouse, database, schemas, tables, a stage pointing to S3, and finally the Snowpipe pipes that automate ingestion.
Create the warehouse:
-- Create the warehouse
-- X-SMALL size = 1 credit per hour
-- AUTO_SUSPEND = 60 means the warehouse stops after 60 minutes of inactivity
-- AUTO_RESUME = TRUE means it starts automatically when a query hits it
CREATE WAREHOUSE IF NOT EXISTS claims_wh
WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE
COMMENT = 'Warehouse for claims pipeline processing';
Create the database and four schemas:
-- Create the main database
CREATE DATABASE IF NOT EXISTS claims_db
COMMENT = 'Healthcare claims analytics database';
-- Create the four schemas
-- RAW: Where Snowpipe lands unprocessed CSV data
-- STAGING: dbt layer 1 - cleaned, typed, renamed data
-- INTERMEDIATE: dbt layer 2 - joins and derived fields
-- MARTS: dbt layer 3 - business-ready aggregates
CREATE SCHEMA IF NOT EXISTS claims_db.raw
COMMENT = 'Raw data from Snowpipe ingestion';
CREATE SCHEMA IF NOT EXISTS claims_db.staging
COMMENT = 'dbt staging layer: cleaned and typed data';
CREATE SCHEMA IF NOT EXISTS claims_db.intermediate
COMMENT = 'dbt intermediate layer: enriched data with joins';
CREATE SCHEMA IF NOT EXISTS claims_db.marts
COMMENT = 'dbt marts layer: business aggregates and KPIs';
-- Verify setup
USE WAREHOUSE claims_wh;
USE DATABASE claims_db;
Create the raw tables:
Each raw table mirrors the schema of its corresponding CSV file. The columns use the correct target data types — Snowflake will attempt to cast the incoming string values from CSV to these types during the COPY INTO operation.
-- CLAIMS table: core claims facts
-- One row per claim submitted
CREATE TABLE IF NOT EXISTS claims (
claim_id VARCHAR(36) NOT NULL,
patient_id VARCHAR(36) NOT NULL,
provider_id VARCHAR(36) NOT NULL,
date_of_service DATE NOT NULL,
diagnosis_code VARCHAR(10),
procedure_code VARCHAR(10),
claim_status VARCHAR(20) NOT NULL,
billed_amount NUMERIC(12, 2),
allowed_amount NUMERIC(12, 2),
paid_amount NUMERIC(12, 2),
paid_date DATE,
_loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
COMMENT = 'Raw claims data from provider submissions';
-- PATIENTS table: patient demographics
-- One row per unique patient ID
CREATE TABLE IF NOT EXISTS patients (
patient_id VARCHAR(36) NOT NULL,
date_of_birth DATE NOT NULL,
gender VARCHAR(10),
plan_id VARCHAR(20),
enrollment_date DATE,
state VARCHAR(2),
_loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
COMMENT = 'Raw patient demographic data';
-- PROVIDERS table: provider reference data
-- One row per unique provider ID
CREATE TABLE IF NOT EXISTS providers (
provider_id VARCHAR(36) NOT NULL,
npi VARCHAR(10),
specialty VARCHAR(50),
network_status VARCHAR(20),
state VARCHAR(2),
_loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
COMMENT = 'Raw provider reference data';
-- CLAIM_LINE_ITEMS table: line-level claim details
-- One row per line item on a claim (a claim can have multiple line items)
CREATE TABLE IF NOT EXISTS claim_line_items (
line_id VARCHAR(36) NOT NULL,
claim_id VARCHAR(36) NOT NULL,
line_number INTEGER,
cpt_code VARCHAR(10),
units INTEGER,
line_amount NUMERIC(12, 2),
_loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
COMMENT = 'Raw claim line item data';
-- Verify tables exist
SELECT table_name FROM information_schema.tables WHERE table_schema = 'RAW' ORDER BY table_name;
Create the S3 stage:
A Snowflake stage is a named pointer to an external storage location, in this case, your S3 bucket. It tells Snowflake where to look for files, but does not copy anything yet.
Security note: Do not use IAM user access keys in production stages. Use the IAM role you created in Step 4 with Snowflake's storage integration feature. The example below uses placeholder values to illustrate the structure only.
-- Step 1: Create a named stage pointing to your S3 bucket
-- The stage is just a pointer to S3. It doesn't copy anything yet.
CREATE STAGE IF NOT EXISTS s3_claims_stage
URL = 's3://anish-shilpakar-bucket/claims_dw/raw'
CREDENTIALS = (
AWS_KEY_ID = 'AKIA47PU4CRAWV6VOIBU'
AWS_SECRET_KEY = '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'
)
COMMENT = 'S3 stage for claims-pulse raw data';
Create the CSV file format:
Snowflake needs to know how to parse the incoming files. This file format definition tells it exactly what to expect.
-- Step 2: Create a file format for CSV parsing
-- Field delimiter = comma (obviously)
-- Skip header row (our CSVs have headers)
-- NULL string handling: empty values become NULL in Snowflake
CREATE FILE FORMAT IF NOT EXISTS csv_format
TYPE = 'CSV'
COMPRESSION = 'AUTO'
FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n'
SKIP_HEADER = 1
NULL_IF = ('')
EMPTY_FIELD_AS_NULL = TRUE
COMMENT = 'Standard CSV format for claims data';
Create the Snowpipe pipes:
A pipe is the automation unit in Snowpipe. It combines a trigger (new SQS message = new file in S3) with an execution rule (run this COPY INTO statement). Unlike a scheduled batch job, pipes are event-driven — they fire the moment a new file arrives, not on a clock.
ON_ERROR = CONTINUE means that if one row fails to load (for example, a malformed date that cannot be cast), Snowpipe skips that row and continues loading the rest of the file. This is intentional in a pipeline where data quality is handled downstream by dbt tests.
-- Step 3: Create pipes for each table
-- A pipe = trigger + execution rule. When a file lands in S3, Snowpipe automatically runs COPY.
-- Pipes are continuous and event-driven (unlike Airflow DAGs which are scheduled).
CREATE PIPE claims_pipe AS
COPY INTO claims (claim_id, patient_id, provider_id, date_of_service, diagnosis_code,
procedure_code, claim_status, billed_amount, allowed_amount,
paid_amount, paid_date)
FROM @s3_claims_stage/claims/
FILE_FORMAT = csv_format
ON_ERROR = CONTINUE;
CREATE PIPE patients_pipe AS
COPY INTO patients (patient_id, date_of_birth, gender, plan_id, enrollment_date, state)
FROM @s3_claims_stage/patients/
FILE_FORMAT = csv_format
ON_ERROR = CONTINUE;
CREATE PIPE providers_pipe AS
COPY INTO providers (provider_id, npi, specialty, network_status, state)
FROM @s3_claims_stage/providers/
FILE_FORMAT = csv_format
ON_ERROR = CONTINUE;
CREATE PIPE claim_line_items_pipe AS
COPY INTO claim_line_items (line_id, claim_id, line_number, cpt_code, units, line_amount)
FROM @s3_claims_stage/claim_line_items/
FILE_FORMAT = csv_format
ON_ERROR = CONTINUE;
Check the existing pipes using the following command
SHOW PIPES IN SCHEMA claims_db.raw;
Also, you can list the files in S3 stage using the following command
-- List files in S3 stage
LIST @claims_db.raw.s3_claims_stage/claims/;
LIST @claims_db.raw.s3_claims_stage/patients/;
LIST @claims_db.raw.s3_claims_stage/providers/;
LIST @claims_db.raw.s3_claims_stage/claim_line_items/;
And the following commands can be used to trigger a manual refresh of these pipes
-- Refresh to process files
ALTER PIPE claims_pipe REFRESH;
ALTER PIPE patients_pipe REFRESH;
ALTER PIPE providers_pipe REFRESH;
ALTER PIPE claim_line_items_pipe REFRESH;
Step 6: Env File Configuration
With AWS and Snowflake fully configured, collect all the credentials and identifiers into a single .env file. The pipeline reads from this file, nothing is hardcoded.
# ============================================================================
# SNOWFLAKE CONFIGURATION
# Fill these in with your Snowflake trial account details
# ============================================================================
SNOWFLAKE_ACCOUNT=your_account_identifier
SNOWFLAKE_USER=your_username
SNOWFLAKE_PASSWORD=your_password
SNOWFLAKE_WAREHOUSE=claims_wh
SNOWFLAKE_DATABASE=claims_db
SNOWFLAKE_SCHEMA=raw
# ============================================================================
# AWS CONFIGURATION
# Paste your AWS IAM credentials here
# ============================================================================
AWS_ACCESS_KEY_ID=YOUR_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY=YOUR_SECRET_ACCESS_KEY
AWS_REGION=us-east-1
AWS_S3_BUCKET=YOUR_BUCKET_NAME
AWS_S3_PREFIX=claims_dw/raw
AWS_SNS_TOPIC_ARN=YOUR_SNS_TOPIC_ARN
AWS_SQS_QUEUE_ARN=YOUR_SQS_QUEUE_ARN
AWS_ACCOUNT_ID=YOUR_AWS_ACCOUNT_ID
# ============================================================================
# DBT CONFIGURATION
# ============================================================================
DBT_PROFILES_DIR=/home/ace/Documents/Projects/DE-Projects/Snowflake/claims-pulse
# ============================================================================
# PIPELINE CONFIGURATION
# ============================================================================
CLAIMS_OUTPUT_DIR=/tmp/claims_output
NUM_RECORDS=50000
2. Generating Realistic Data
Most portfolio projects use clean, perfectly formatted data. Real healthcare data is not clean. I wanted this project to reflect actual working conditions, so the generator intentionally introduces three categories of defects that mirror real billing system failures.
# ====================================================
# DEFECT 1: 3% NULL diagnosis codes
# Real-world: Provider submits claim without ICD-10 code
# ====================================================
if random.random() < 0.03:
diagnosis_code = None
# ====================================================
# DEFECT 2: 2% paid > billed
# Real-world: Payment processing bug or refund error
# ====================================================
if random.random() < 0.02:
paid_amount = billed_amount + random.uniform(100, 5000)
# ====================================================
# DEFECT 3: 1% paid_date < date_of_service
# Real-world: System timestamp recording error
# ====================================================
if random.random() < 0.01:
paid_date = date_of_service - timedelta(days=random.randint(1, 30))
The generator produces four CSV files at scale: approximately 50,000 claims, 5,000 patients, 500 providers, and 100,000+ claim line items. These approximate realistic data volumes for a mid-sized payer in a single market.
Data Schemas
| File |
Key Columns |
claims.csv |
claim_id, patient_id, provider_id, date_of_service, diagnosis_code, procedure_code, claim_status, billed_amount, allowed_amount, paid_amount, paid_date |
patients.csv |
patient_id, date_of_birth, gender, plan_id, enrollment_date, state |
providers.csv |
provider_id, npi, specialty, network_status, state |
claim_line_items.csv |
line_id, claim_id, line_number, cpt_code, units, line_amount |
3. S3 as the Landing Zone
Why S3, and Not a Direct Load Into Snowflake?
Putting S3 in the middle of this architecture is a deliberate design decision, not just a convention.
Decoupling ingestion from compute. If Snowflake is temporarily unavailable — maintenance, quota issue, configuration error — your data sits safely in S3. You can replay ingestion from S3 at any time. Without S3 as a buffer, a Snowflake outage during a file arrival means that data is simply gone.
Enabling an event-driven model. S3 can publish event notifications the moment a file lands in a configured prefix. Snowpipe subscribes to these events through SQS. This replaces the traditional model of running COPY INTO on a schedule — you are not checking for new files every 15 minutes; the arrival of a file itself triggers the load.
Creating a durable audit trail. With versioning enabled, S3 preserves every version of every file. Access logs and CloudTrail integration record exactly who accessed what and when. For healthcare data, this is not optional — it is a compliance requirement.
Folder Structure
We partition the landing zone by table name:
s3://your-bucket/
└── claims_dw/
└── raw/
├── claims/
│ └── claims.csv
├── patients/
│ └── patients.csv
├── providers/
│ └── providers.csv
└── claim_line_items/
└── claim_line_items.csv
Each table gets its own prefix. This means each Snowpipe pipe watches an independent path, one table's failures or delays do not affect the others.
Uploading Files with boto3
import boto3
import os
from dotenv import load_dotenv
load_dotenv()
class S3Uploader:
def __init__(self, bucket, prefix, region):
self.bucket = bucket
self.prefix = prefix
self.s3_client = boto3.client(
's3',
region_name=region,
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY')
)
def upload_file(self, local_path, s3_key):
self.s3_client.upload_file(local_path, self.bucket, s3_key)
Pre-Upload Validation with Great Expectations
The single most important architectural decision in this pipeline is where data quality validation happens. The answer: before S3, not after.
# In upload_to_s3.py (main entry point)
def main():
# Step 1: Validate BEFORE upload
validation_passed = run_ge_validation(CLAIMS_OUTPUT_DIR)
if not validation_passed:
# Abort — don't upload bad data to S3
exit(1)
# Step 2: Upload only if validation passed
uploader = S3Uploader(bucket, prefix, region)
uploader.upload_claims_pipeline_data(CLAIMS_OUTPUT_DIR)
The Great Expectations suite runs 56 validation rules across the four CSV files before any file touches S3. If a file fails validation, the upload aborts entirely. No bad data enters the pipeline.
# Sample expectations from claims_expectations.json
{
"expectation_type": "expect_table_columns_to_match_ordered_list",
"kwargs": {
"column_list": ["claim_id", "patient_id", "provider_id", ...]
}
},
{
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": { "column": "claim_id" }
},
{
"expectation_type": "expect_column_values_to_match_regex",
"kwargs": {
"column": "claim_status",
"regex": "^(paid|denied|pending|appealed)$"
}
}
The suite validates column structure and order, row count ranges, primary key uniqueness, null constraints on required fields, regex patterns for medical codes (ICD-10, CPT, NPI), and numeric ranges (billed amount must be greater than zero and less than $1M).
Event Driven Ingestion from S3: S3 → SNS → SQS → Snowpipe
Here is how all the AWS infrastructure you set up in Step 1-3 works together at runtime:
New file arrives in S3
↓
S3 fires ObjectCreated event → SNS Topic
↓
SNS delivers message to → SQS Queue
↓
Snowpipe polls SQS, reads message
↓
Snowpipe executes COPY INTO on the referenced file
↓
Data appears in Snowflake raw table (~1–5 minutes latency)
Each service in this chain has a distinct, non-overlapping role:
S3 is the trigger — it fires a reliable ObjectCreated event for every file, every time, including the bucket name, object key, file size, and timestamp.
SNS is the fan-out hub — it receives the S3 event and distributes it to all subscribers. All four Snowpipe pipes share one SNS topic, each receiving the same events through their own SQS subscriptions.
SQS is the durability buffer — it stores events for up to 14 days, decoupling Snowpipe's consumption schedule from S3's event firing. Messages that fail processing move to the Dead Letter Queue after 3 attempts.
Snowpipe is the consumer — it continuously polls SQS, reads incoming messages, runs COPY INTO for each referenced file, and deletes the message from SQS on success.
Raw data loaded by Snowpipe is flat, untyped, and unjoined. It is not useful for analytics in that form. dbt takes that raw data and builds it into clean, structured outputs through three transformation layers, a pattern commonly called the Medallion Architecture.
The Medallion Pattern with dbt
Raw data alone isn't useful for analytics. We need to clean it, enrich it, and aggregate it. dbt handles this with a three-layer architecture:
Raw Tables (Snowpipe loads)
↓ [Staging Layer]
Clean, typed views
↓ [Intermediate Layer]
Enriched, joined views
↓ [Marts Layer]
Business aggregate tables
A key point about materialization:
Staging and intermediate models are built as views. They are computed at query time, always reflecting the latest data in the raw tables. When Snowpipe loads a new file, your staging views immediately show those records — no dbt run required.
Mart models are built as tables. They are materialized snapshots, optimized for BI tool performance. These need a dbt run --select marts to refresh after new data arrives.
Layer 1: Staging — Defensive Type Casting
The staging layer has one job: take raw string data from CSV and produce safely typed, consistently formatted columns. Nothing more.
-- stg_claims.sql
SELECT
claim_id,
patient_id,
provider_id,
-- TRY_CAST instead of CAST — bad data returns NULL, not an error
TRY_CAST(date_of_service AS DATE) AS date_of_service,
UPPER(TRIM(diagnosis_code)) AS diagnosis_code, -- Can be NULL (defect!)
UPPER(TRIM(procedure_code)) AS procedure_code,
LOWER(TRIM(claim_status)) AS claim_status,
TRY_CAST(billed_amount AS NUMERIC(12,2)) AS billed_amount,
TRY_CAST(allowed_amount AS NUMERIC(12,2)) AS allowed_amount,
TRY_CAST(paid_amount AS NUMERIC(12,2)) AS paid_amount,
TRY_CAST(paid_date AS DATE) AS paid_date
FROM {{ source('raw_claims', 'claims') }}
Why TRY_CAST instead of CAST?
CAST fails the entire query if a single row has malformed data. In a 50,000-row claims table, one bad date value would crash the entire staging model. TRY_CAST converts bad values to NULL silently and lets the pipeline continue. You then catch those NULLs with dbt tests in a controlled way, rather than having the pipeline fail unpredictably.
The intermediate layer enriches claims with patient and provider context, and derives business-critical calculated fields.
-- int_claims_enriched.sql
SELECT
c.*,
p.date_of_birth,
p.gender,
pv.specialty,
pv.network_status,
-- Business derived fields
DATEDIFF(DAY, c.date_of_service, c.paid_date) AS days_to_payment,
c.paid_amount / NULLIF(c.billed_amount, 0) AS payment_ratio,
c.paid_amount > c.billed_amount AS is_payment_exceeds_billed,
DATEDIFF(YEAR, p.date_of_birth, c.date_of_service) AS patient_age_at_service,
pv.network_status = 'out-of-network' AS is_out_of_network
FROM {{ ref('stg_claims') }} c
LEFT JOIN {{ ref('stg_patients') }} p ON c.patient_id = p.patient_id
LEFT JOIN {{ ref('stg_providers') }} pv ON c.provider_id = pv.provider_id
Why LEFT JOIN and not INNER JOIN?
An INNER JOIN silently drops any claim where the patient or provider record is missing. In healthcare billing, a missing provider reference is a data quality issue — but it does not mean the claim stops existing. Analysts still need to see that claim, even with NULLs in the provider columns. LEFT JOIN preserves every claim and surfaces data gaps as NULLs, which dbt tests can then flag explicitly.
Why NULLIF(c.billed_amount, 0) in the payment ratio?
Division by zero in SQL does not throw an error in all databases — some return NULL, others crash the query. NULLIF(billed_amount, 0) converts a zero billed amount to NULL before the division happens, making the behavior explicit and consistent across any SQL engine.
Layer 3: Marts — Business Aggregates
Three mart tables power the analytics layer, each answering a different business question:
mart_claims_summary: Monthly trends by claim status
SELECT
DATE_TRUNC('month', date_of_service) AS year_month,
claim_status,
COUNT(DISTINCT claim_id) AS total_claims,
ROUND(AVG(payment_ratio), 4) AS avg_payment_ratio,
ROUND(AVG(days_to_payment), 1) AS avg_days_to_payment,
SUM(CASE WHEN claim_status = 'denied' THEN 1 ELSE 0 END)
/ NULLIF(COUNT(*), 0) AS denial_rate
FROM {{ ref('int_claims_enriched') }}
GROUP BY DATE_TRUNC('month', date_of_service), claim_status
mart_provider_performance: Denial rates, payment efficiency, and out-of-network activity by provider. This is the table a claims operations team would open first when investigating a spike in denials.
mart_diagnosis_analysis: Cost and denial patterns grouped by ICD-10 category. Uses LEFT(diagnosis_code, 3) to group related diagnosis codes — for example, all codes starting with J06 represent upper respiratory infections, regardless of their specific fourth or fifth character.
5. Data Quality Testing — Two Layers
Layer 1: Great Expectations (Pre-S3)
As covered in Section 3, Great Expectations runs before any file is uploaded. If validation fails, the upload aborts. This is the gate that stops structurally malformed data from ever entering the pipeline.
Validated rules include:
Column structure and order matches expected schema
Row count falls within expected range
Primary key columns are unique and non-null
Required fields have no null values
Medical codes match regex patterns (ICD-10, CPT, NPI format)
Numeric ranges are reasonable (billed amount between $0 and $1M)
Layer 2: dbt Tests (Post-Transformation)
After dbt transforms the data, tests validate the outputs in Snowflake. These catch issues that survived Great Expectations, either because they are too subtle for a structural check, or because they only become visible after joining tables.
Standard column tests in schema.yml:
# schema.yml — standard tests
- name: claim_id
tests:
- not_null
- unique
- name: patient_id
tests:
- not_null
- relationships:
to: ref('stg_patients')
field: patient_id
- name: claim_status
tests:
- accepted_values:
values: ['paid', 'denied', 'pending', 'appealed']
The Custom Test: Catching Business Logic Violations
Standard schema tests check whether a column exists, is unique, or has valid values. They cannot check whether the relationship between columns makes business sense. For that, you write custom singular SQL tests.
The most important test in this pipeline checks a rule that should never be violated in a properly functioning claims system:
-- tests/assert_paid_not_exceed_billed.sql
-- Business Rule: PAID_AMOUNT must never exceed BILLED_AMOUNT
-- Returns rows that VIOLATE the rule.
-- dbt marks test as FAILED if any rows are returned.
SELECT
claim_id,
billed_amount,
paid_amount,
(paid_amount - billed_amount) AS overpayment_amount
FROM {{ ref('int_claims_enriched') }}
WHERE paid_amount > billed_amount
ORDER BY overpayment_amount DESC
Expected result in production: 0 rows.
Actual result with the intentional 2% defect rate: approximately 1,000 rows.
When this test runs and fails, I can say with confidence: "Our pipeline detected 1,084 overpayment records representing $2.3M in potential financial exposure. In production, this result would trigger an immediate alert to the Claims Operations team for remediation."
That is the difference between a pipeline that processes data and a pipeline that understands the data it is processing.
What's Next?
This post covered the full first half of the claims-pulse pipeline: generating realistic healthcare data with intentional defects, validating it before S3, loading it into Snowflake through an event-driven AWS chain (S3 → SNS → SQS → Snowpipe), and transforming it into analytics-ready outputs with dbt. The pipeline can currently run end-to-end by executing the generation, validation, upload, and dbt run steps manually in sequence.
In Part 2, I will introduce Apache Airflow to orchestrate all of these components into a single automated workflow. That post will walk through configuring Airflow with Docker Compose and building DAGs that wire together every stage of this pipeline.