Real-Time Data Engineering: Streaming Unstructured Data to AWS with Apache Spark
I am a computer engineering undergraduate highly interested in Data engineering, Artificial intelligence, Machine Learning and Natural language processing. I like exploring and learning new technologies and I will be writing various blogs here during my learning journey
Introduction
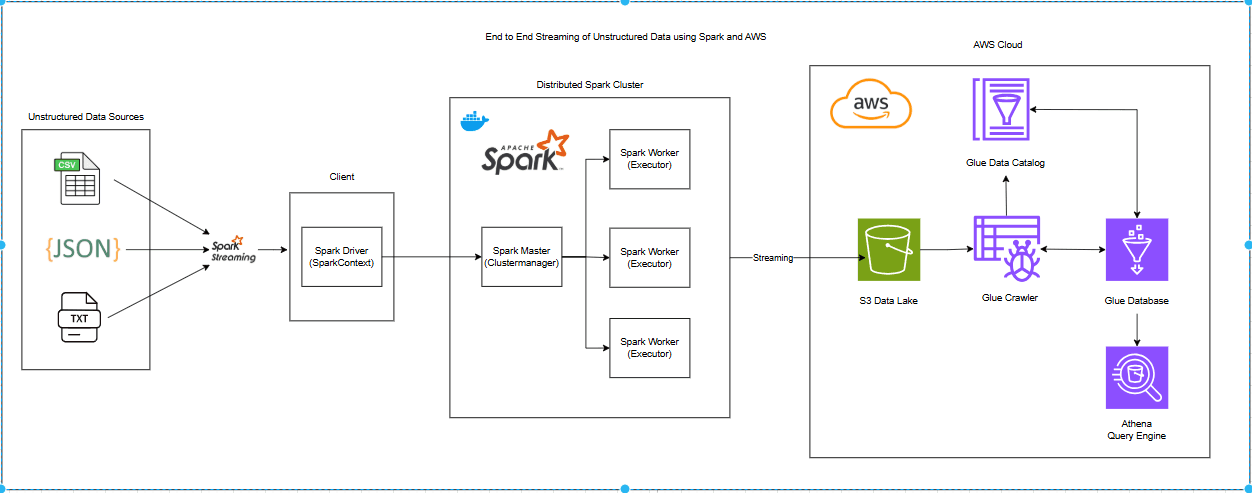
In the era of big data, organizations generate vast amounts of unstructured data in formats such as JSON, CSV, and TXT files. Processing and analyzing this data efficiently is crucial for real-time decision-making. This project demonstrates an end-to-end data streaming pipeline using Apache Spark Streaming, Docker, and AWS services to handle unstructured data seamlessly. The pipeline ingests JSON, CSV, and TXT files via Spark Streaming, processes them in a distributed Spark cluster, and stores them in an S3 Data Lake. An AWS Glue Crawler extracts metadata and updates the Glue Data Catalog, enabling Athena to query the data efficiently. The goal is to demonstrate how data engineers can automate real-time processing of unstructured data and seamlessly integrate it with AWS services for storage, metadata management, and analytics.
Architecture

About Unstructured Data
Unstructured data refers to information that does not have a predefined schema or organized format, making it difficult to store, process, and analyze using traditional relational databases. Unlike structured data, which is neatly arranged in rows and columns (e.g., SQL databases), unstructured data lacks a consistent structure and can exist in various formats such as text, images, videos, audio, and logs. With the rapid growth of data-driven applications, organizations generate massive volumes of unstructured data from social media, IoT sensors, emails, customer reviews, and machine logs. Data engineers play a crucial role in extracting valuable insights from this data by designing scalable pipelines that ingest, process, and analyze it efficiently. Big data technologies such as Apache Spark, Hadoop, and AWS services help process unstructured data and transform it into a usable format for analytics and decision-making.
Unstructured data accounts for nearly 80-90% of the world’s data and continues to grow exponentially. Some real-world examples include:
Text Data: Emails, chat messages, customer feedback, PDFs, and reports.
Multimedia: Images, videos, and audio recordings from platforms like YouTube or surveillance systems.
Logs and Machine Data: Server logs, application logs, IoT sensor data, and cybersecurity logs.
Social Media Content: Tweets, Facebook posts, Instagram captions, and TikTok videos.
Here in this project, I am using unstructured data sources as source which include text files, and some semistructured data including CSV and JSON files. The examples of files in the source are shown below:
TXT file
Pr111 Product: Parle-G Biscuit Category: Food Costs Rs.20 Best From 2024-05-01 to 2025-05-01About 100 such files are generated in the source by using a simple Python script as shown below:
import random import datetime def generate_random_product(index): categories = { "Food": [ "Parle-G Biscuit", "Dairy Milk Chocolate", "Lay's Chips", "Oreo Cookies", "Maggie Noodles", "Kellogg's Corn Flakes", "KitKat", "Bournvita", "Tropicana Juice", "Pepsi" ], "Personal Care": [ "Colgate Toothpaste", "Dove Shampoo", "Lifebuoy Soap", "Nivea Cream", "Vaseline Lotion", "Garnier Face Wash", "Old Spice Deodorant", "Himalaya Face Pack", "Gillette Razor", "Head & Shoulders Shampoo" ], "Footwear": [ "Nike Running Shoes", "Adidas Sneakers", "Puma Sandals", "Reebok Sports Shoes", "Skechers Loafers", "Woodland Boots", "Bata Formal Shoes", "Crocs Slippers", "Fila Trainers", "New Balance Sneakers" ], "Electronics": [ "Samsung Galaxy S21", "Apple iPhone 14", "Sony Headphones", "JBL Bluetooth Speaker", "Dell Laptop", "HP Printer", "LG Smart TV", "Canon DSLR Camera", "Fitbit Smartwatch", "Logitech Keyboard" ] } category = random.choice(list(categories.keys())) product = random.choice(categories[category]) product_code = f"Pr{1000 + index}" cost = random.randint(1000, 10000) # Random cost between Rs.10 and Rs.500 start_date = datetime.date.today() + datetime.timedelta(days=random.randint(0, 365)) end_date = start_date + datetime.timedelta(days=365) content = f""" {product_code} Product: {product} Category: {category} Costs Rs.{cost} Best From {start_date} to {end_date} """.strip() return content def save_to_file(content, filename): with open(filename, "w") as file: file.write(content) print(f"File '{filename}' has been created with random product details.") if __name__ == "__main__": for i in range(1, 101): # Generate 100 files with unique product codes product_details = generate_random_product(i) file_path = f"./source_files/txt_source/product_details_{i}.txt" save_to_file(product_details, file_path)
CSV file
p_id,p_name,p_category,p_price,p_created_date,p_expiry_date Pr1,Power Motors,Electronics,2500,2025-01-01,2025-09-30JSON file
{ "p_id": "Pr11", "p_name": "Gaming Mouse", "p_category": "Computer", "p_price": 1000, "p_created_date": "2023-09-10", "p_expiry_date": "2026-05-10" }
About Apache Spark and Spark Streaming
Apache Spark is an open-source, distributed computing framework designed for fast and scalable big data processing. Unlike traditional batch processing systems, Spark performs computations in memory, significantly improving performance. It follows a Master-Slave architecture, where a Spark Master manages the cluster, and multiple Spark Workers (Executors) execute tasks in parallel. Spark Streaming is a real-time data processing engine that enables micro-batch processing of streaming data. It can ingest data from various sources like Kafka, Flume, AWS S3, and file systems, process it using Spark’s DAG (Directed Acyclic Graph) execution model, and output results to databases, dashboards, or cloud storage making it ideal for log analysis, fraud detection and IOT applications
To simplify Spark deployment, Docker is used to containerize Spark components, ensuring portability, scalability, and ease of configuration. Using Docker Compose, we define Spark’s cluster setup, including one master node and three worker nodes, making the environment easily replicable across different systems. The docker-compose file for spark configuration is shown below:
version: '3.8'
x-spark-common: &spark-common
image: bitnami/spark:3.5.1
volumes:
- ./jobs:/opt/bitnami/spark/jobs
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_MASTER_URL: spark://spark-master:7077
networks:
- spark-network
restart: always
services:
spark-master:
image: bitnami/spark:3.5.1
volumes:
- ./jobs:/opt/bitnami/spark/jobs
command: bin/spark-class org.apache.spark.deploy.master.Master
ports:
- "9090:8080"
- "7077:7077"
networks:
- spark-network
restart: always
spark-worker-1:
<<: *spark-common
spark-worker-2:
<<: *spark-common
spark-worker-3:
<<: *spark-common
networks:
spark-network:
driver: bridge
The provided Docker Compose file configures Spark with:
Spark Master: Runs on port 7077 and manages the cluster.
Three Spark Workers: Each with 1 CPU core and 1GB memory (
SPARK_WORKER_CORES: 1,SPARK_WORKER_MEMORY: 1g).Volumes: Mounted to share Spark jobs (
./jobs:/opt/bitnami/spark/jobs). This jobs folder includes the actual spark job which will read the unstructured data from source files, parse them, and store them in the AWS S3 data lake.Network Bridge:
spark-networkenables inter-coAntainer communication.Auto Restart: Ensures the services restart automatically in case of failure.
About AWS Services Involved
Amazon S3 as a Data Lake for Streaming Unstructured Data**
Amazon Simple Storage Service (S3) is a highly scalable and durable object storage service that serves as the foundation for building data lakes in AWS. A data lake is a centralized repository that allows storing structured, semi-structured, and unstructured data at any scale. In this project, Spark Streaming reads unstructured files (CSV, JSON, TXT), processes them into structured data using Spark DataFrames, and writes the output as Parquet files to S3, making it ready for analytics.
For configuring S3 as a data lake, firstly new access keys were set up using AWS IAM. The following were the steps taken
Firstly navigate to AWS Console and then search for IAM
Then select Users > user_name > Create Access Key. You will be redirected to the screen as shown below

Select the command line interface and tick on confirmation, this will then create new access keys and you will be redirected to a new screen as shown below

Here you can copy the access key and secret access key and store them in a safe location as these keys will later be used for accessing S3 buckets for storing the parsed data. Alternatively, the keys can also be downloaded as a CSV file.
The next step is creating a new S3 bucket which will be used to store the parsed data.
For this search for AWS S3 and navigate to AWS S3. Click on Create New Bucket.
Here configure the bucket as shown below, choose an appropriate name that should be globally unique.

Initially, the S3 bucket will be empty, but once we run the spark job, this bucket will be populated by folders like checkpoints and data which is dynamically created by the spark job.
AWS Glue
AWS Glue is a fully managed ETL (Extract, Transform, Load) service that enables seamless data discovery, cataloging, and transformation in the AWS ecosystem. In this project, Glue plays a critical role in making the unstructured data queryable and analyzable after being processed by Spark Streaming and stored in Amazon S3 as Parquet files.
Key Components of AWS Glue in This Project
Glue Crawler
A Glue Crawler scans the S3 bucket detects new Parquet files, and extracts metadata such as column names, data types, and table structure.
It automatically updates the Glue Data Catalog, ensuring that any new or updated data is discoverable.
The crawler runs periodically to detect new files added to S3 as part of the Spark Streaming pipeline.
Glue Data Catalog
Acts as a centralized metadata repository, storing schema details for all discovered datasets.
Enables seamless integration with AWS Athena, Redshift, and other AWS analytics services.
Provides a unified view of structured data extracted from unstructured files stored in S3.
Glue Database and Tables
The Glue Crawler creates a new table inside a designated Glue Database based on the schema detected in the S3 data lake.
Each time new files arrive in S3, the table is automatically updated to reflect the changes.
The Glue database acts as a logical grouping for related datasets, making it easy to manage and query structured data.
Here the crawler will create a table named bronze.
To configure AWS Glue, the following steps are taken
Firstly search for AWS Glue in the IAM console and navigate to Glue

Then navigate to the Crawlers page to create a new glue crawler

Configure a new crawler as shown below.

Here we need to add the S3 bucket path of the source folder as the data source as shown below.


Also, we need to create a new IAM role to allow the crawler to create a new table.


After creating IAM role, we also have to create new glue database to store the tables as shown below.




Once the crawler is created, we can run the crawler to crawl the data from the S3 data lake and to create a new table in the AWS Glue database.

AWS Athena
AWS Athena is a serverless, interactive query service that allows users to analyze structured data stored in Amazon S3 using standard SQL. In this project, Athena plays a crucial role in querying the processed unstructured data after it has been streamed, structured, and cataloged by Apache Spark and AWS Glue.
After the Glue crawler creates a new table, AWS Athena can be used to query this newly created table. But before querying we need to do some configuration in AWS Athena.
For this navigate to AWS Athena by searching it in AWS Management console. Here we need to configure query result location where we configure S3 location to store query results.

End-to-End Workflow Explanation
The end-to-end workflow for this project follows these steps:
Uploading Source Files
- Firstly, Input files (TXT, CSV, JSON) are uploaded into designated S3 source folders.

Spark Job Processing
Spark reads and processes these files using appropriate methods:
CSV & JSON: Directly loaded into Spark DataFrames.
TXT Files: Processed using regular expressions and user-defined functions (UDFs) to extract required fields.
For example, UDFs extract details like
product_id,product_name,category,price, and dates.
Spark Job Code
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, IntegerType, DateType
from pyspark.sql.functions import udf, regexp_replace
from config.config import configuration
from datetime import datetime
import re
def extract_p_id(file_content):
file_content = file_content.strip()
# First word of the file is the product id
match = re.search(r'^(\w+)', file_content)
p_id = match.group(1) if match else None
return p_id
def extract_p_name(file_content):
# search for Product: <product_name>
match = re.search(r'Product:\s*(.+)', file_content)
p_name = match.group(1).strip() if match else None
return p_name
def extract_p_category(file_content):
# search for Category: <product_category>
match = re.search(r'Category:\s*(.+)', file_content)
p_category = match.group(1).strip() if match else None
return p_category
def extract_p_price(file_content):
# Search for Costs Rs.<price>
match = re.search(r'Costs\s*Rs\.(\d+)', file_content)
price = float(match.group(1)) if match else None
return price
def extract_dates(file_content):
match = re.search(r'Best From\s*(\d{4}-\d{2}-\d{2})\s*to\s*(\d{4}-\d{2}-\d{2})', file_content)
if match:
start_date = datetime.strptime(match.group(1), '%Y-%m-%d')
end_date = datetime.strptime(match.group(2), '%Y-%m-%d')
return start_date, end_date
return None, None
def define_udfs():
return {
'extract_p_id_udf': udf(extract_p_id, StringType()),
'extract_p_name_udf': udf(extract_p_name, StringType()),
'extract_p_category_udf': udf(extract_p_category, StringType()),
'extract_p_price_udf': udf(extract_p_price, DoubleType()),
'extract_dates_udf': udf(extract_dates, StructType([
StructField('p_created_date', DateType(), True),
StructField('p_expiry_date', DateType(), True)
])),
}
def streamWriter(input: DataFrame, checkpointFolder, output):
return (
input
.writeStream
.outputMode('append')
.format('parquet')
.option('path', output)
.option('checkpointLocation', checkpointFolder)
.trigger(processingTime='5 seconds')
.start()
)
if __name__ == '__main__':
# Initialize the Spark session
spark = (
SparkSession.builder.appName('Unstructured_Data_Streaming_Spark_AWS')
.config("spark.jars.packages",
'org.apache.hadoop:hadoop-aws:3.3.1,'
'com.amazonaws:aws-java-sdk:1.11.469')
.config('spark.hadoop.fs.s3a.impl','org.apache.hadoop.fs.s3a.S3AFileSystem')
.config('spark.hadoop.fs.s3a.access.key',configuration.get('AWS_ACCESS_KEY'))
.config('spark.hadoop.fs.s3a.secret.key',configuration.get('AWS_SECRET_KEY'))
.config('spark.hadoop.fs.s3a.aws.credentials.provider','org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider')
.getOrCreate()
)
# Variables for source files
txt_src_dir = 'file:///opt/bitnami/spark/jobs/source_files/txt_source'
csv_src_dir = 'file:///opt/bitnami/spark/jobs/source_files/csv_source'
json_src_dir = 'file:///opt/bitnami/spark/jobs/source_files/json_source'
# define data schema
# p_id,p_name,p_category,p_price,p_create_date,p_expiry_date
data_schema = StructType([
StructField('p_id', StringType(), True),
StructField('p_name', StringType(), True),
StructField('p_category', StringType(), True),
StructField('p_price', DoubleType(), True),
StructField('p_created_date', DateType(), True),
StructField('p_expiry_date', DateType(), True),
])
# define udfs
udfs = define_udfs()
# reading from a file stream
txt_file_df = (
spark.readStream
.format('text')
.option('wholetext','true')
.load(txt_src_dir)
)
txt_file_df = txt_file_df.withColumn('p_id', regexp_replace(udfs['extract_p_id_udf']('value'), r'\r',' '))
txt_file_df = txt_file_df.withColumn('p_name', udfs['extract_p_name_udf']('value'))
txt_file_df = txt_file_df.withColumn('p_category', udfs['extract_p_category_udf']('value'))
txt_file_df = txt_file_df.withColumn('p_price', udfs['extract_p_price_udf']('value'))
txt_file_df = txt_file_df.withColumn('p_create_date', udfs['extract_dates_udf']('value').getField('p_created_date'))
txt_file_df = txt_file_df.withColumn('p_expiry_date', udfs['extract_dates_udf']('value').getField('p_expiry_date'))
txt_parsed_df = txt_file_df.select('p_id', 'p_name', 'p_category', 'p_price', 'p_create_date', 'p_expiry_date')
# reading from json source
json_df = (
spark.readStream
.json(json_src_dir,schema=data_schema,multiLine=True)
)
# reading from csv source
csv_df = (
spark.readStream
.format('csv')
.option('header', 'true')
.schema(data_schema)
.load(csv_src_dir)
)
# union all the dataframes
src_union_df = txt_parsed_df.union(json_df).union(csv_df)
# to write the dataframe into s3 data lake in parquet format
query = streamWriter(src_union_df, checkpointFolder='s3a://anish-shilpakar-bucket/checkpoints', output='s3a://anish-shilpakar-bucket/data/spark_unstructured/bronze')
#to display the read stream in console as output
# query = (
# src_union_df
# .writeStream
# .outputMode('append')
# .format('console')
# .option('truncate', False)
# .start()
# )
query.awaitTermination()
spark.stop()
This Spark application is designed to process unstructured text, CSV, and JSON files, extract meaningful information, and store the structured data in AWS S3 as Parquet files. Code Explanation
Importing Required Libraries:
Uses
pyspark.sqlfor Spark DataFrames, UDFs, and schema definitions.Imports
reanddatetimefor text processing and date parsing.
Text Processing Functions:
Defines UDFs (User-Defined Functions) using Regular Expressions (RegEx) to extract:
p_id: Extract the product ID (first word).p_name: Extract the product name (after "Product:").p_category: Extract the product category (after "Category:").p_price: Extract the product price (after "Costs Rs.").p_created_date&p_expiry_date: Extract validity dates (after "Best From").
Spark Streaming Initialization:
Creates a SparkSession with AWS S3 configurations for accessing the data lake.
Uses credentials from a config file (
configuration.get('AWS_ACCESS_KEY')).The configuration.py stores required access keys for S3 buckets as shown below
configuration = { 'AWS_ACCESS_KEY': '...', 'AWS_SECRET_KEY': '...' }
Reading Input Files (TXT, CSV, JSON) as Streams:
Text Files: Read as raw text and processed using UDFs.
JSON & CSV: Read using Spark's built-in schema inference.
Data Transformation:
Extracts required fields from TXT files using UDFs.
Ensures data consistency by applying the same schema across JSON, CSV, and parsed TXT data.
Combines (unions) data from all sources into a single data frame.
Streaming Data to S3:
Uses
writeStreamto continuously write the structured data into AWS S3 in Parquet format.A checkpoint directory is maintained in S3 for fault tolerance.
Execution and Monitoring:
The query runs continuously, processing new files every 5 seconds (
trigger(processingTime='5 seconds')).Optionally, data can be displayed in the console for debugging.
The spark session is stopped after execution.
Executing the Spark Job
To run the job locally in local spark
spark-submit main.py
To run the job inside a docker-based distributed spark cluster
docker exec -it docker_setup-spark-master-1 spark-submit --master spark://spark-master:7077 jobs/main.py
Once the spark job starts running, we can see that it reads the source files, creates dataframes and start streaming the results as parquet files in the s3 data lake.
On inspecting logs, we can see results like shown below:

Once reading all files is completed and when no new files are added the logs show that the query has been idle as shown below

Inspecting S3 Storage
The Spark job creates two folders in S3:
Checkpoints Folder:
Stores metadata required for Spark Structured Streaming to track processed data and ensure fault tolerance.
Contains subfolders like:
commits/: Stores commit logs for processed batches.metadata/: Maintains streaming query metadata.offsets/: Tracks data read offsets to prevent duplicate processing.sources/: Stores source-related metadata for tracking input data streams.
Data Folder (Bronze Layer): Stores processed Parquet files.
Contains the processed and structured data in Parquet format stored in an S3 Data Lake.
The Bronze layer holds raw ingested data before further transformations.
Includes
_spark_metadata/for tracking written files and multiple.parquetfiles containing structured records.



Running AWS Glue Crawler
Once the parquet files are created and stored by the spark job inside the S3 data lake, we will now run the Glue crawler which we have previously configured

Once the Glue crawler run is completed, we can check the tables in glue database and we can see that a new table has been created.


Querying with AWS Athena
Finally, AWS Athena can be used to query the Glue table for structured data analysis.


We can see the query runs successfully and we obtain the desired result
Test Real-Time Streaming
To test whether the real-time streaming is working properly or not, we keep the spark job running by running the docker container and then adding a new file inside one of the source folders. Running spark as a docker container and checking spark UI.


Newly added CSV file with 5 new records

Now if we check the logs of the spark job we can see that it is reading the content from this new file, parsing the content, and storing the resulting parquet files inthe S3 bucket

By inspecting the S3 data lake we can see the newly added file by checking the last modified column

Then we run the glue crawler to update the Glue database

Once the Glue crawler succeeds, we then again query the glue table like before, and this time we can see that the count has increased from 105 to 110 indicating the addition of new records from the newly added CSV file

Conclusion
This project showcases how Apache Spark, AWS S3, Glue, and Athena can work together to build a real-time streaming pipeline for processing unstructured data. We enable seamless data analysis by continuously ingesting TXT, CSV, and JSON files, transforming them into a structured format, and storing them efficiently in Parquet on S3. With Glue crawlers automating schema detection and Athena providing instant querying, this setup ensures a smooth, scalable, and efficient data processing workflow. Whether for real-time analytics, reporting, or further transformations, this approach lays a solid foundation for handling streaming data in the cloud. This project can now be further enhanced to transform the data in the Bronze layer, store processed data in a data warehouse like Redshift, and integrate with BI tools like AWS QuickSight or Power BI for deeper insights and visualization.