Introduction
In today's world, data is growing at an exponential rate. While this data holds immense value and has the potential to impact various aspects of our world, extracting value from such large datasets is no simple task. This is where data analytics comes in. Data analytics is a process used in the field of data science to examine large datasets, uncovering hidden patterns, correlations, trends, insights, and relationships. These insights can help organizations gain a competitive edge in the market by making data-driven decisions, improving operational efficiency, and identifying new business opportunities. The main tasks involved in data analytics include data collection, cleaning, processing, and analysis.
In my previous blog, I discussed ELT and data lakes, highlighting their importance in the current big data world. This blog continues that discussion by showcasing the power of AWS tools like AWS Glue and AWS Athena for illustrating data analytics on the AWS platform. But before we delve into that, let's first understand what AWS Glue and AWS Athena are and why they are used in data engineering. AWS Glue is a serverless data integration service that simplifies the process of data discovery, preparation, movement, and integration from multiple sources. It offers data crawlers that can automatically infer schema from data stored in data lakes like S3 buckets and create a centralized data catalog. The Glue data catalog serves as a metastore containing metadata for all the crawled tables. Additionally, AWS Glue allows us to visually create ETL pipelines for transformation and use Spark notebooks to process and transform data. Similarly, Amazon Athena is an interactive query service that enables us to analyze data using standard SQL. Amazon Athena offers two options for analyzing data: using the distributed query engine "Trino" to analyze data in S3, on-premises, or other clouds, or using notebooks to build interactive Spark applications and analyze data using "PySpark" and "Spark SQL".
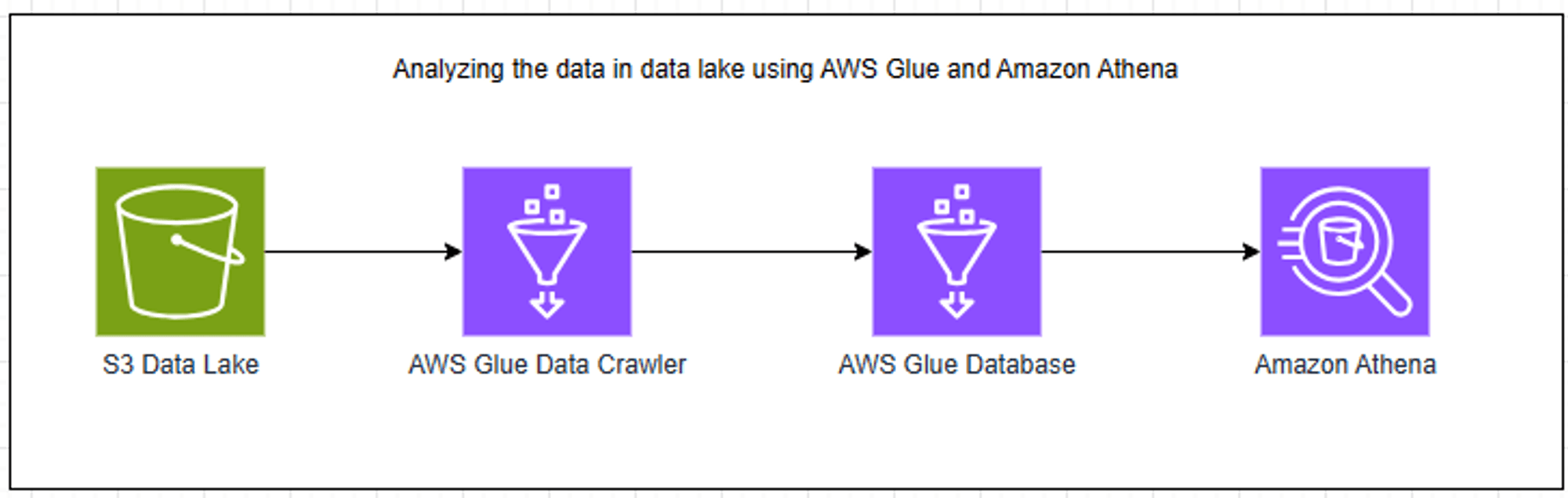
In this blog, I will be using the Trino query engine of Amazon Athena to analyze the data in the Glue database, which was ingested from the S3 data lake using AWS Glue data crawlers. The architecture for this implementation is explained below in the Architecture section.
Architecture
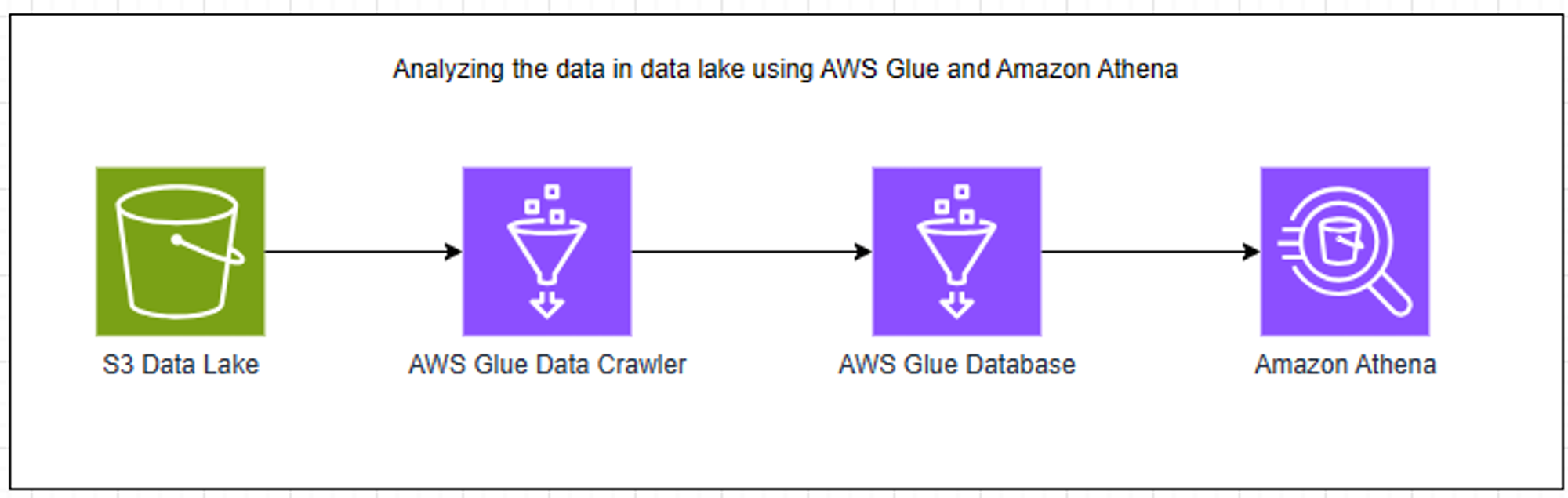
About AWS Glue
AWS Glue is a serverless data integration solution widely used for data analytics in AWS. AWS Glue enables us to connect with over 70 diverse data sources and to manage data in a centralized data catalog. It offers flexible support for different workloads like ETL, ELT, and streaming all in one service and offers services like data discovery, modern ETL, data cleansing, data transformation, and centralized cataloging. The following are some of the main components of AWS Glue
- AWS Glue Data Catalog
AWS Glue data catalog is a fully managed centralized metadata repository and catalog service that stores metadata like table definitions, column names, data types, and other attributes that describe the data used in ETL jobs created in AWS Glue. It helps to simplify and automate the process of data discovery and cataloging, providing a unified view of data across different AWS services and data sources, and making it easier for users to query and analyze the data without having to know the exact location or format of data while still maintaining the data consistency.
- AWS Glue Crawler
AWS Glue Crawler is a feature of AWS Glue that automatically discovers the schema of data in the source and stores the metadata in the AWS Glue Data Catalog. It automates the process of cataloging data making it easier for users to analyze their data without the need to manually define schema for each dataset in the source. AWS Glue crawlers run classifiers which may either be built-in or custom classifiers created by users which automates the process of inferring schema from the dataset saving time and effort for users and allowing them to focus on data analysis and deriving insights from their data.
- AWS Glue Databases
AWS Glue databases are logical containers that store metadata tables in the AWS Glue data catalog. They are used to manage and organize metadata tables which define data from different data stores and make it easy to query data. When a glue data crawler runs on a data source, it will create tables within a specified glue database in the data catalog. Databases help in organizing the tables based on their schema and usage, allowing users to easily locate and access tables they need for analysis and processing.
- AWS Glue ETL
AWS Glue ETL ( Extract, Transform, Load) is a fully managed ETL service provided by AWS that helps users prepare and transform their data for analysis quickly and easily. It simplifies the ETL process by automating tedious tasks like data preparation, data type conversion, and data format conversion and presents itself as a serverless, scalable, and cost-effective solution for data analytics. AWS Glue offers us options for visually creating ETL Jobs as well as writing scripts and spark jobs programmatically for ETL workloads and scheduling the jobs to run as needed. Additionally, it also evaluates and monitors the data quality and provides options for version control by linking the Glue job with a git repository created in AWS Code Commit.
About Amazon Athena
AWS Athena is an interactive query engine service provided by AWS that is used for analyzing the data stored in data lakes like Amazon S3 using standard SQL queries. AWS Athena is a cost-effective, serverless, and highly scalable service that uses the trino query engine and spark in the backend which can run queries in parallel allowing it to generate fast results even for large datasets and complex queries. AWS Athena uses the AWS glue data catalog to query the data sources for data analysis. It also provides options to visualize the query results by integrating with tools like Amazon Quicksight or third-party BI tools to create dashboards and reports that help us understand and communicate the insights gained from data.
Implementation Details
This section describes the various steps taken for implementing a simple data analytics pipeline in AWS using AWS Glue and AWS Athena
Creating AWS Glue Data Crawler
Firstly, navigate to the AWS management console and search for AWS Glue, then open AWS Glue by clicking it.
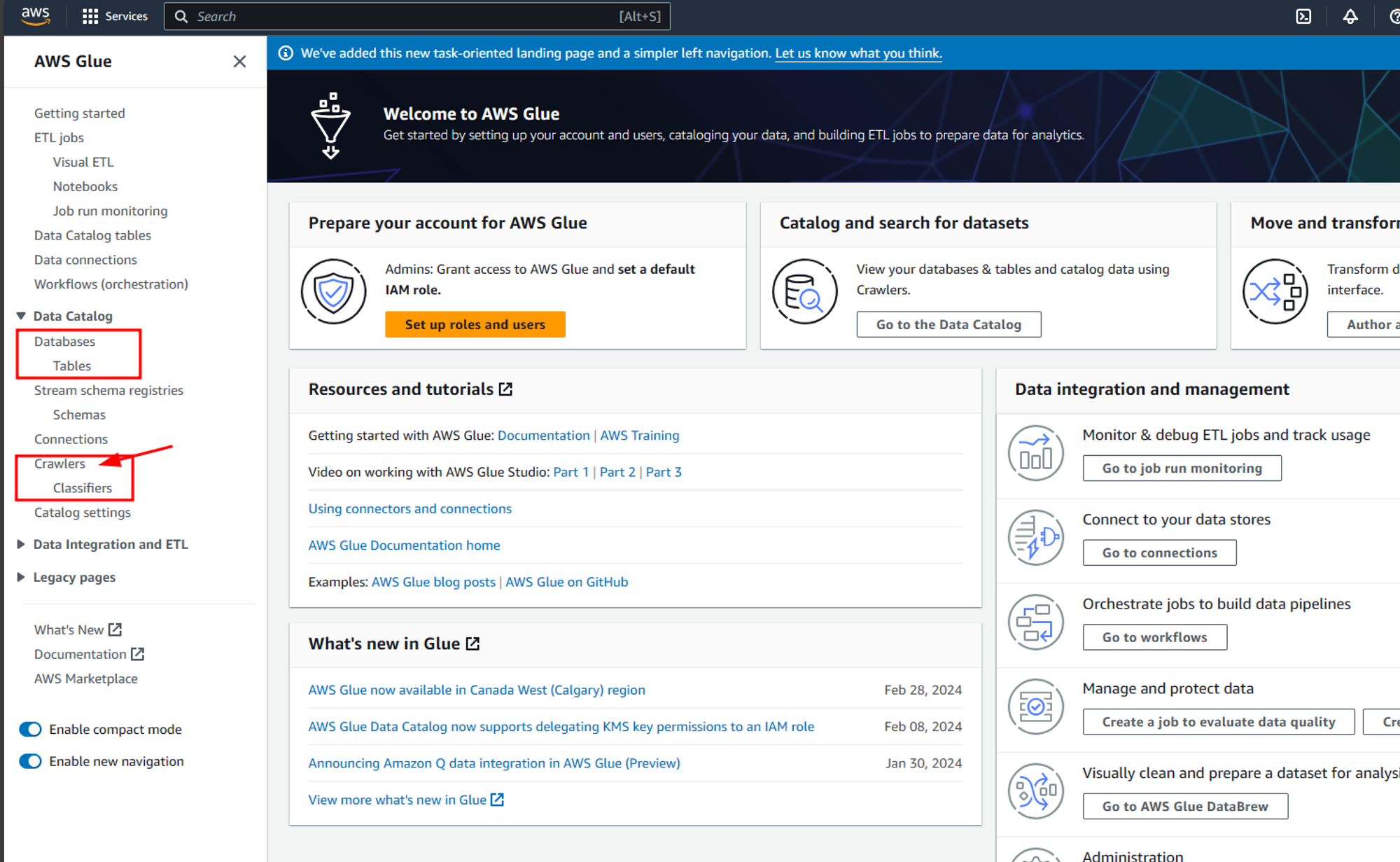
This opens the Glue console as shown below. Here on the left side, you can see various sections like Data Catalog, Data Integration, and ETL and Legacy pages. For this project, we are only dealing with the AWS Glue data catalog and various components of Glue associated with the AWS Glue data catalog. Here we aim to connect AWS Glue with the AWS S3 data lake which we setup in our last blog and to ingest all the data in that S3 data lake for data analysis in AWS Athena.
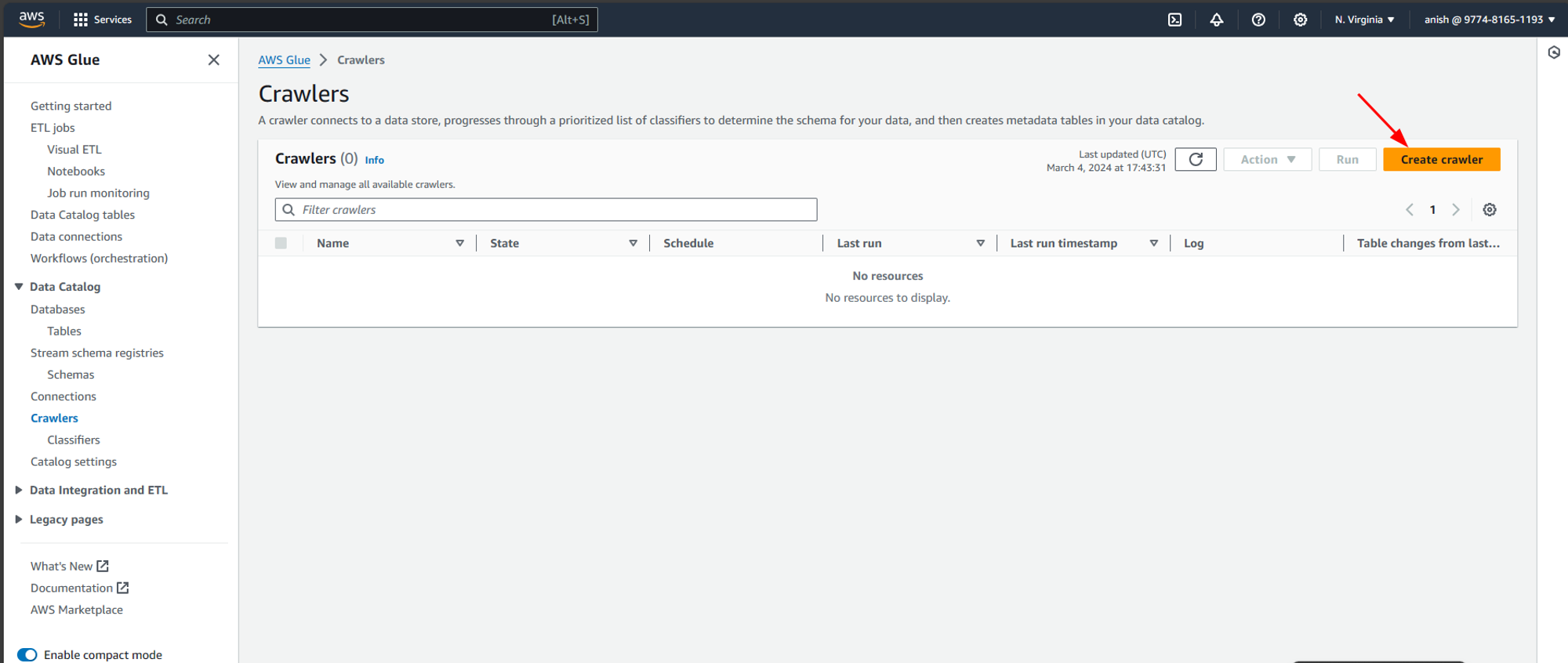
Firstly we navigate to AWS Glue Crawler and create a crawler.
Our original data source was SpaceX API and the raw data from this API is stored in our S3 data lake, so let’s name the glue crawler as spacex_crawler and we can provide a suitable description to the crawler. Also, optionally we can add tags to the cluster. Once done we navigate to the next page.
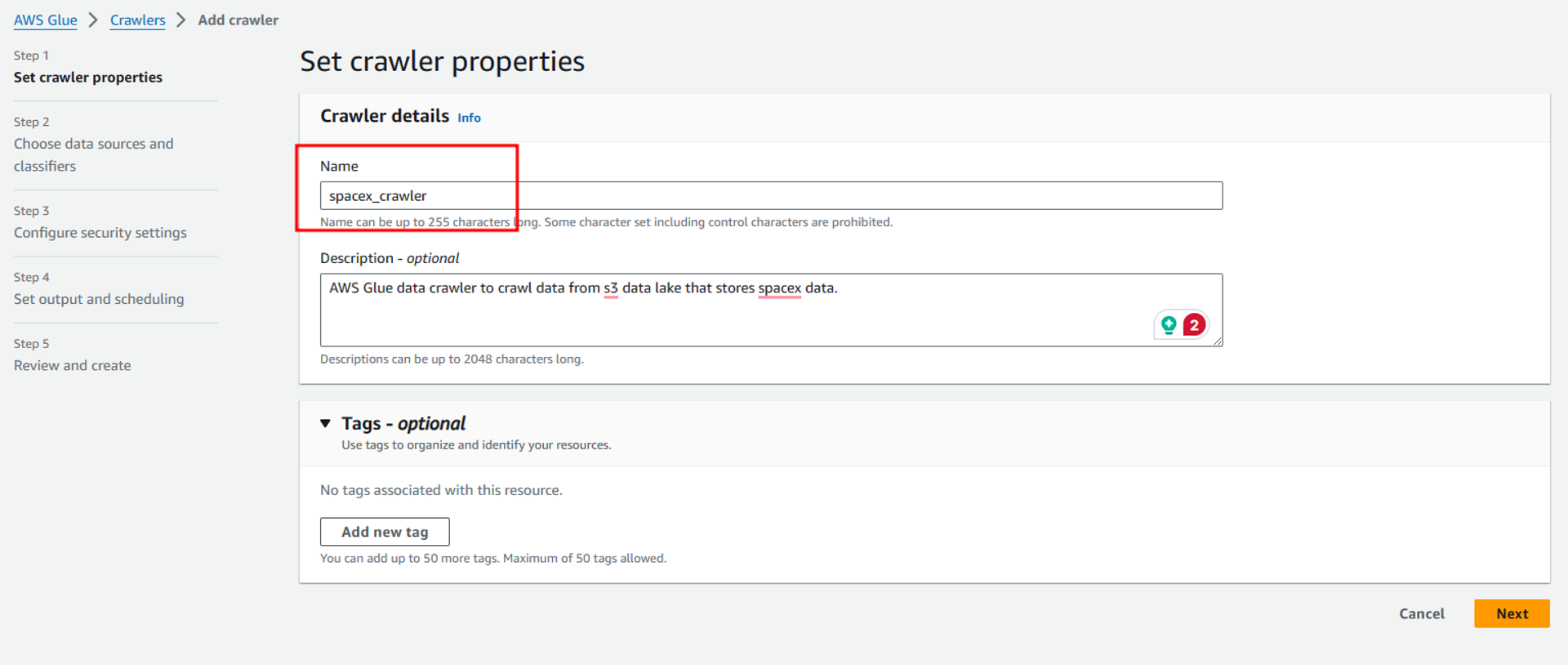
On the next page, we need to configure the data source to ingest and catalog the data. Also, for this project, we don’t need to set up a custom classifier as the built-in classifier available in AWS Glue is capable of inferring schema from the CSV files stored in our s3 data lake.
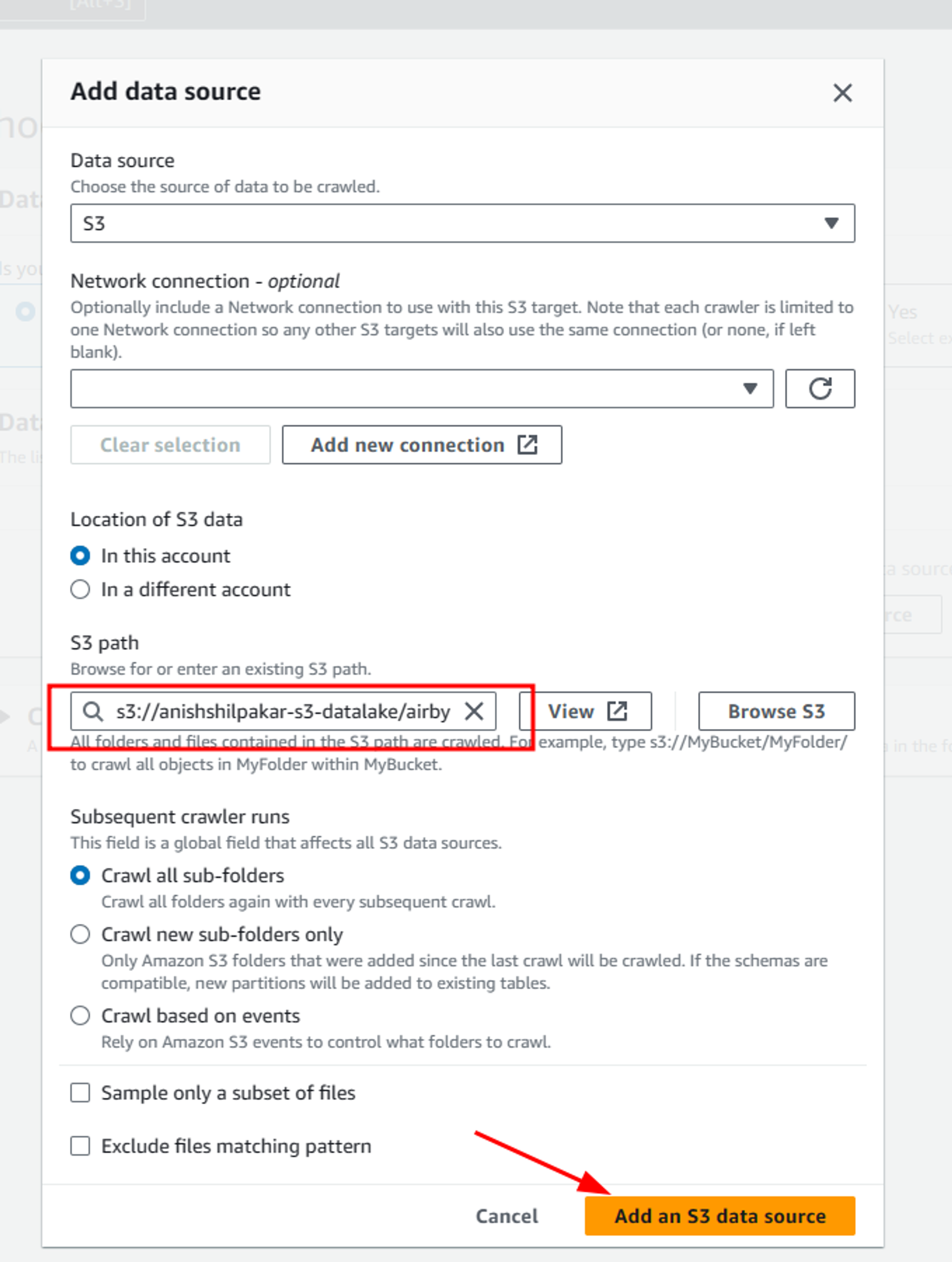
As our data is not already mapped to Glue tables we have to select “Not yet” and click on “Add a data source”
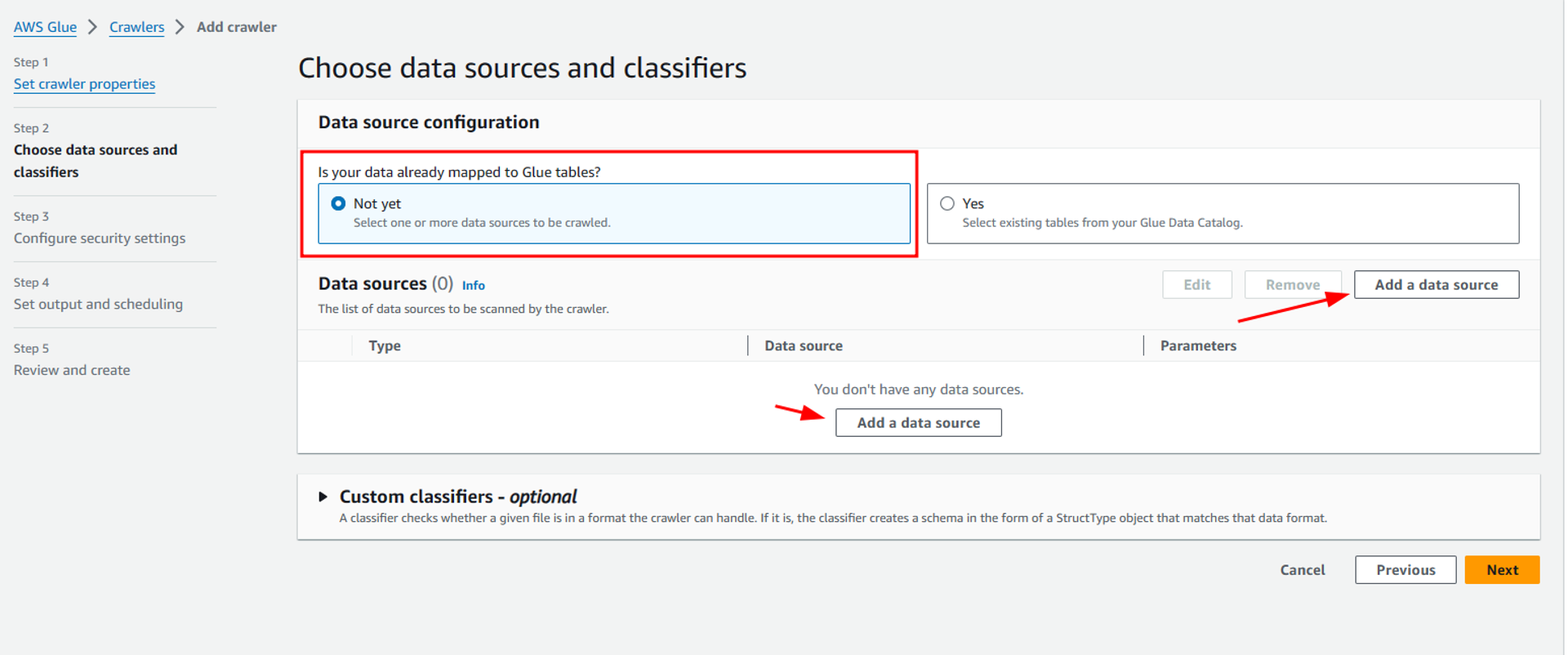
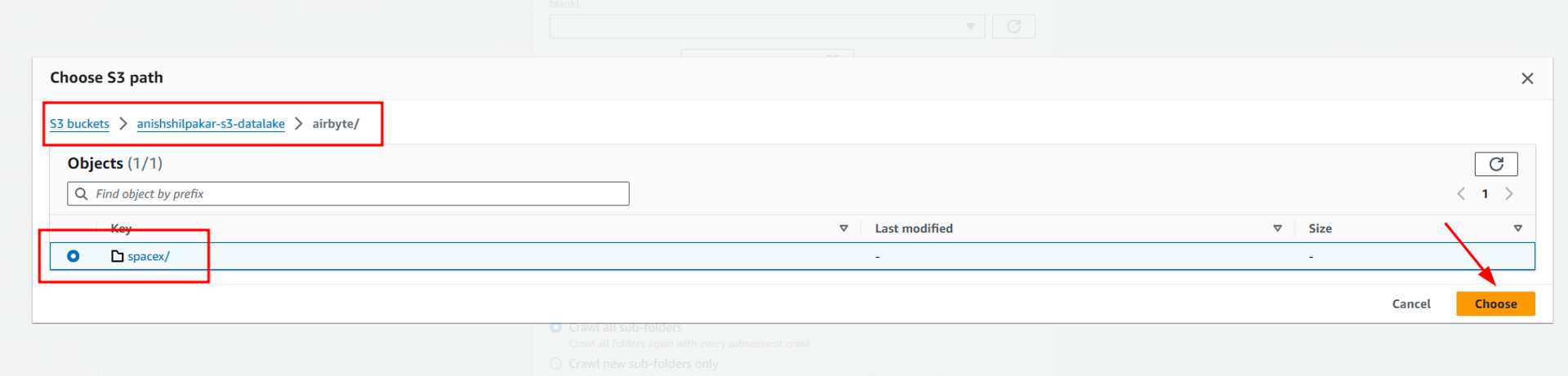
Here select S3 as the data source, choose the location of s3 data as in this account, and then click on browse S3 to select the S3 path of airbyte folder which stores all the data that was ingested from airbyte to our S3 data lake. Also select crawl all sub-folders options, as airbyte ingests data from multiple API endpoints and stores them into multiple folders in our S3 bucket. Then select “Add an S3 data source”.
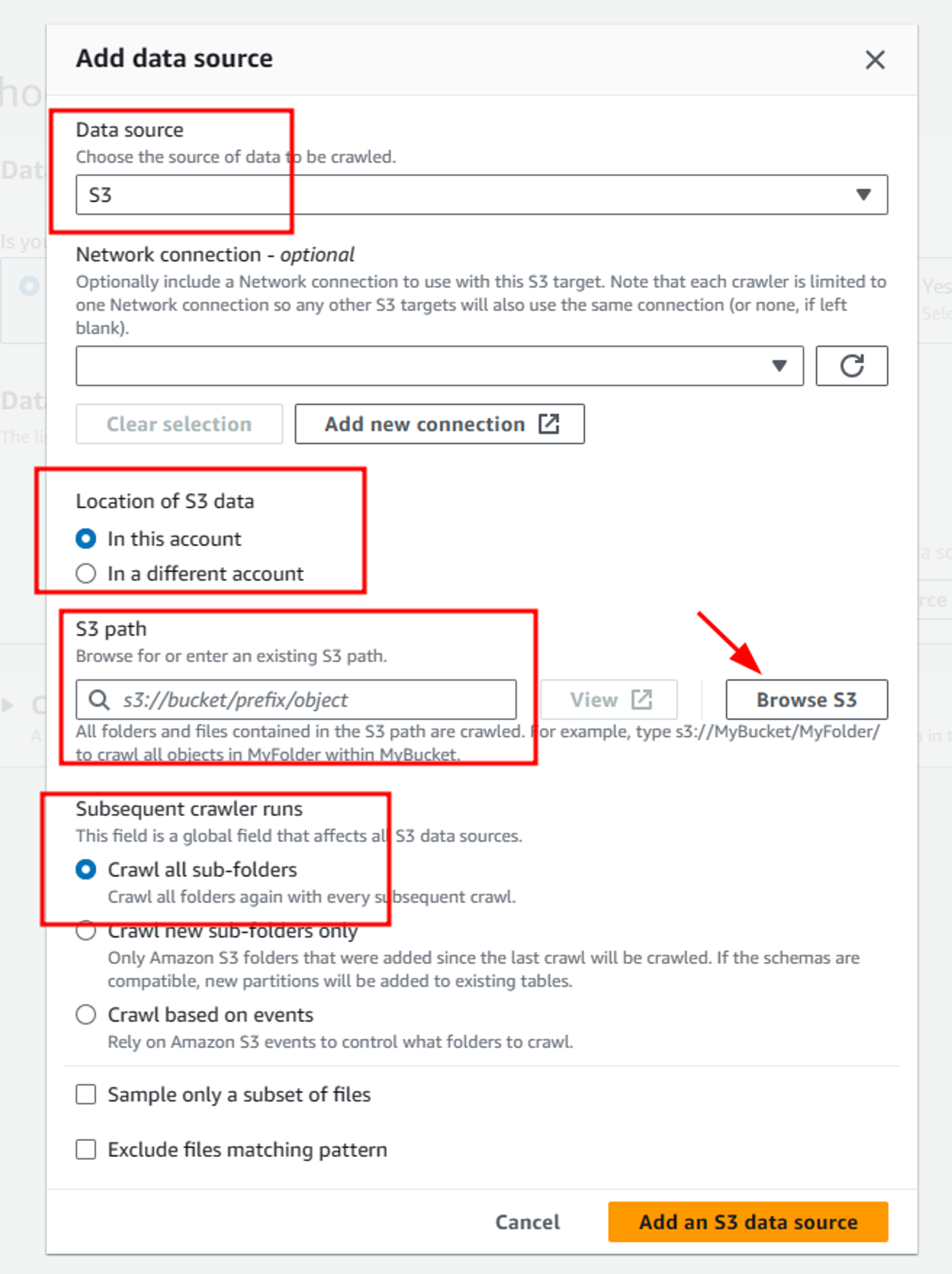
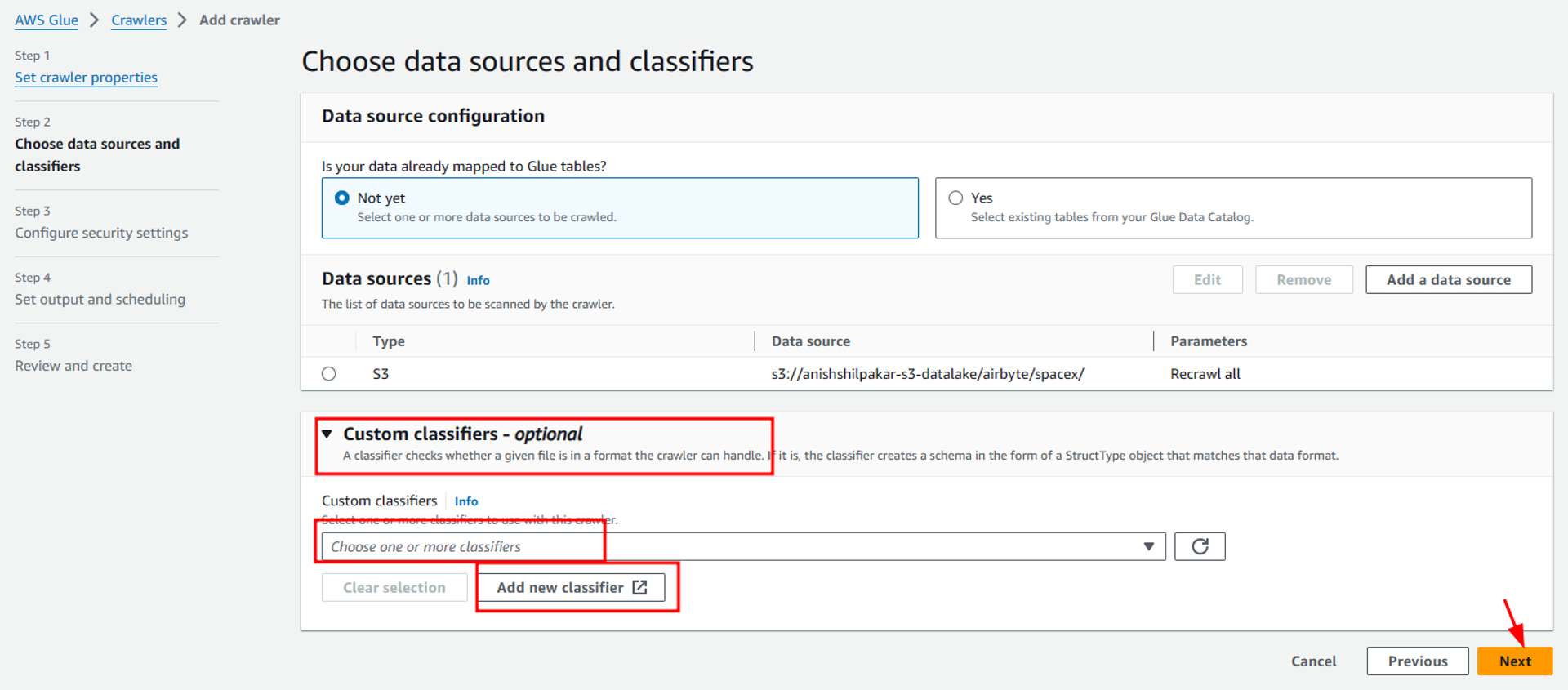
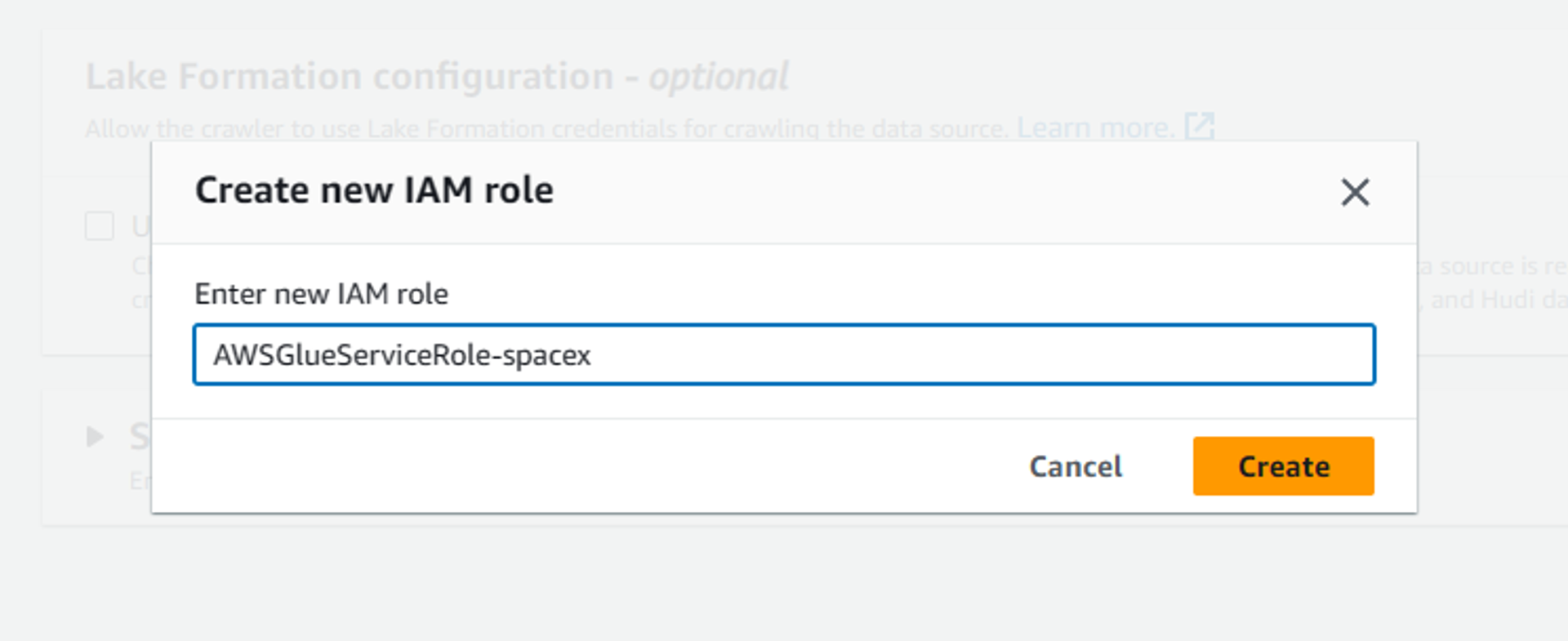
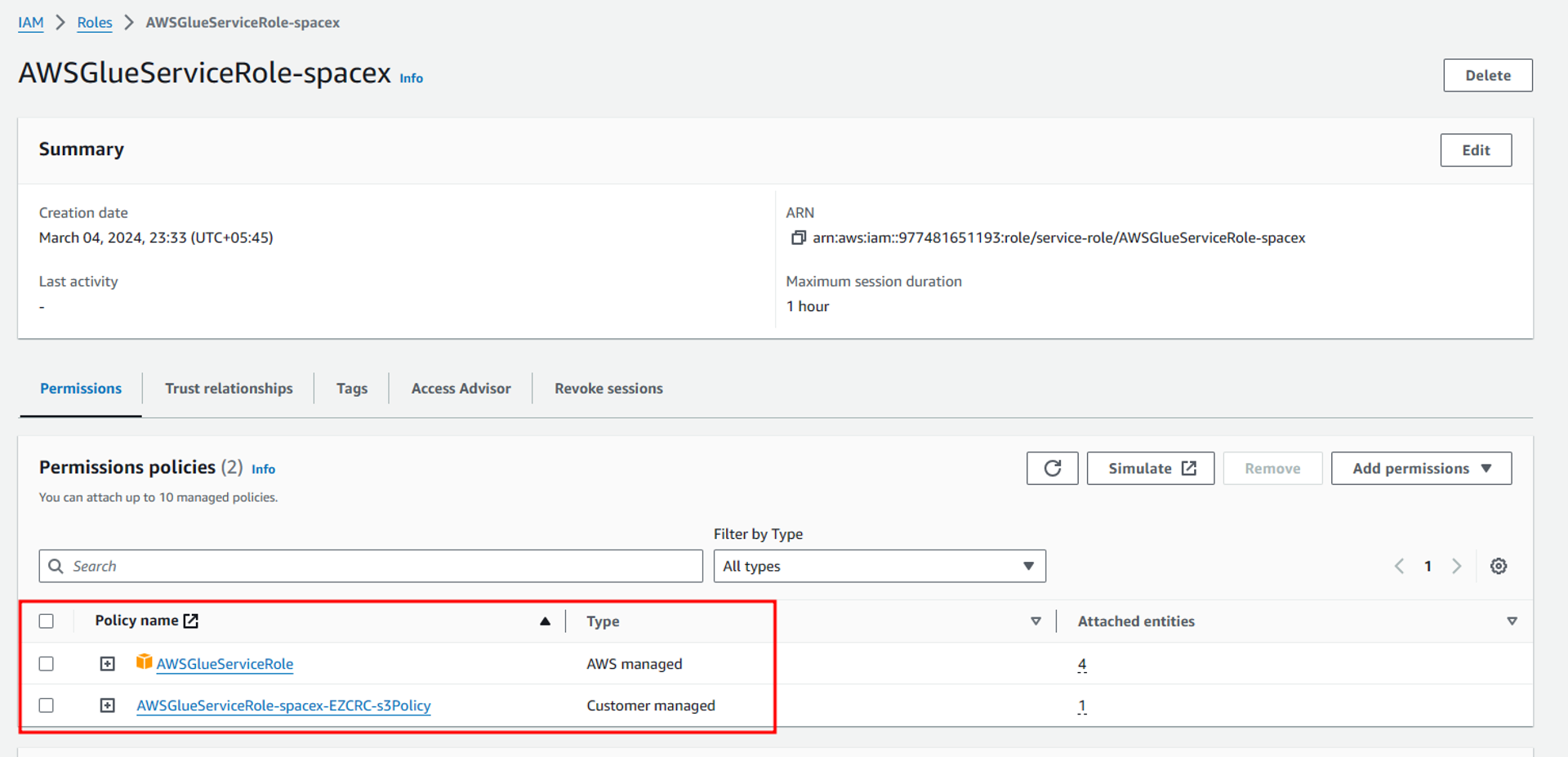
In the next step, we will configure a new IAM role which will provide us necessary access to our S3 buckets. Select the Create new IAM role option inside configure security settings and then provide a suitable name to your IAM role. This automatically creates a new IAM role with all necessary permissions required to access the files from the s3 bucket as shown below. Once the role is configured, click on Next and navigate to the new page.
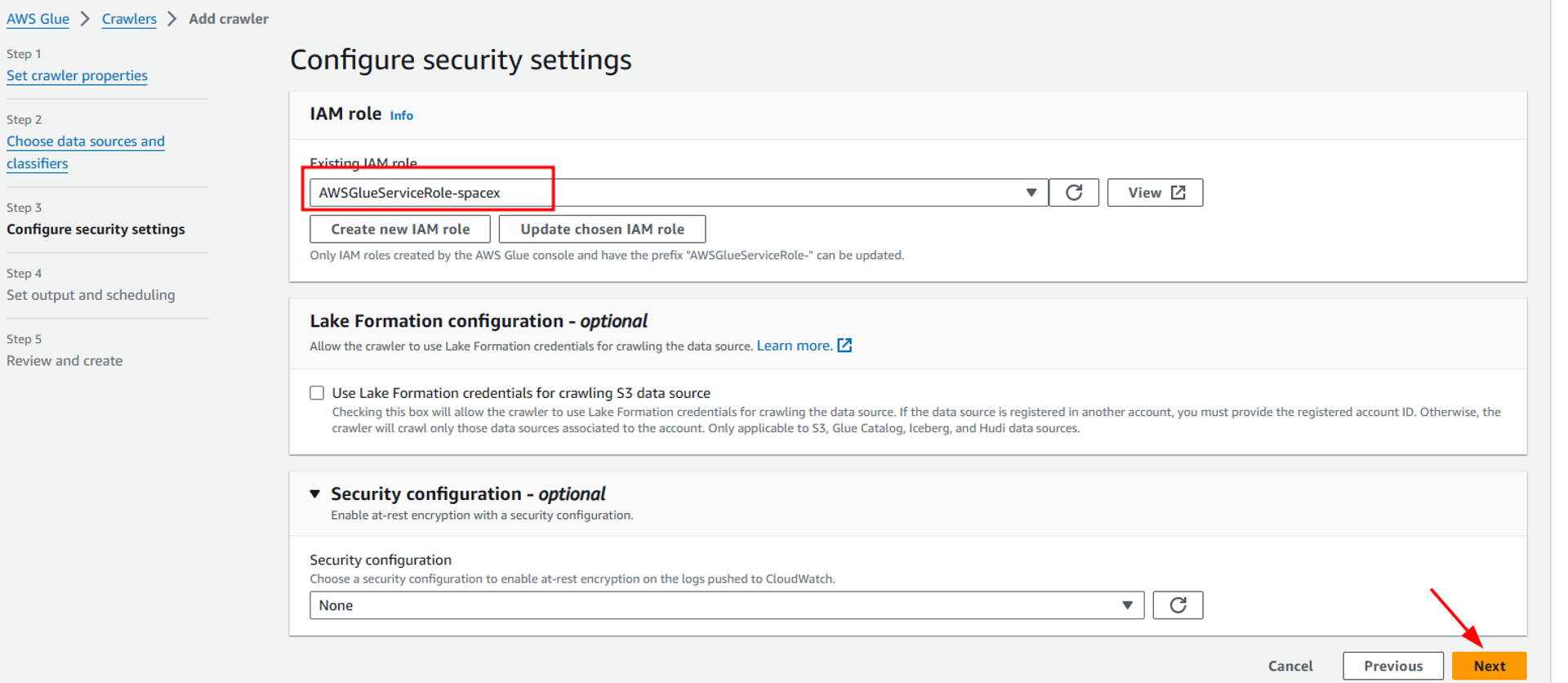
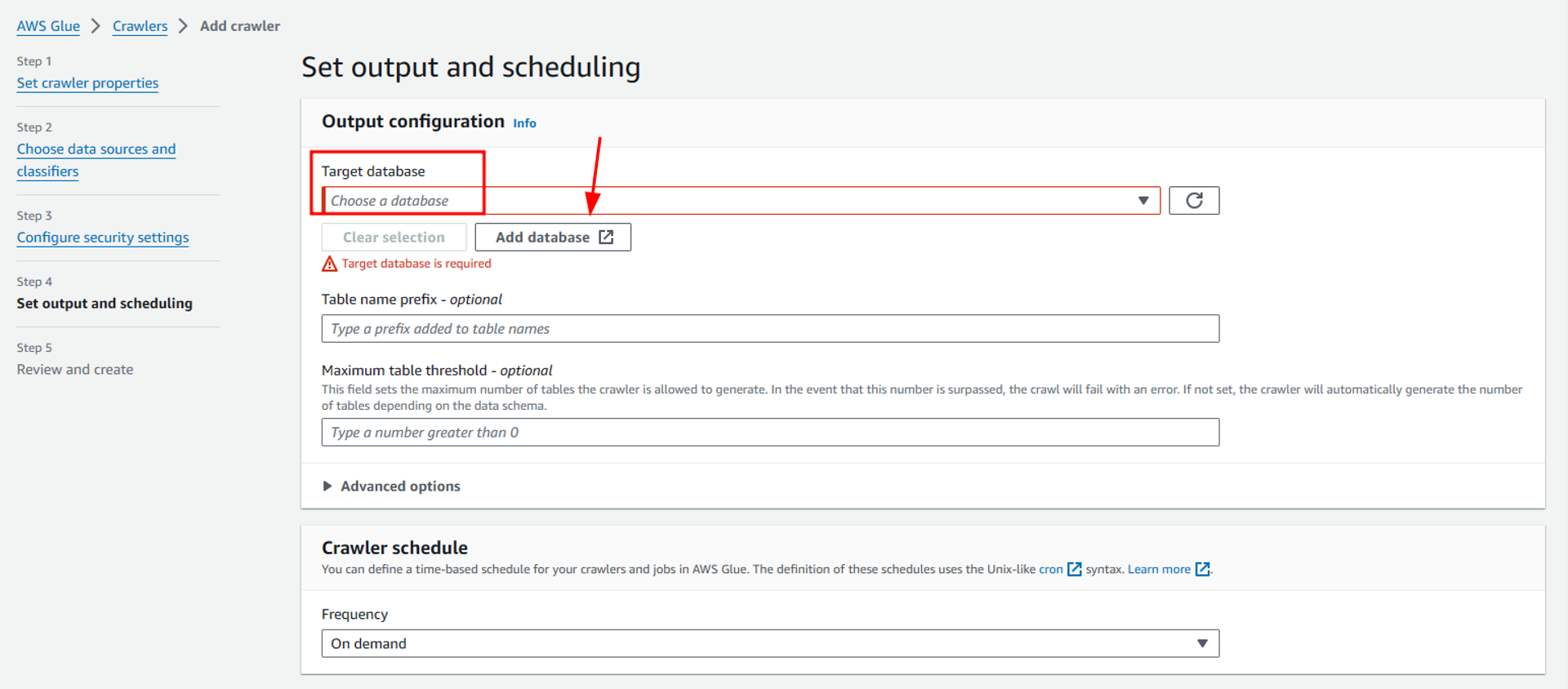
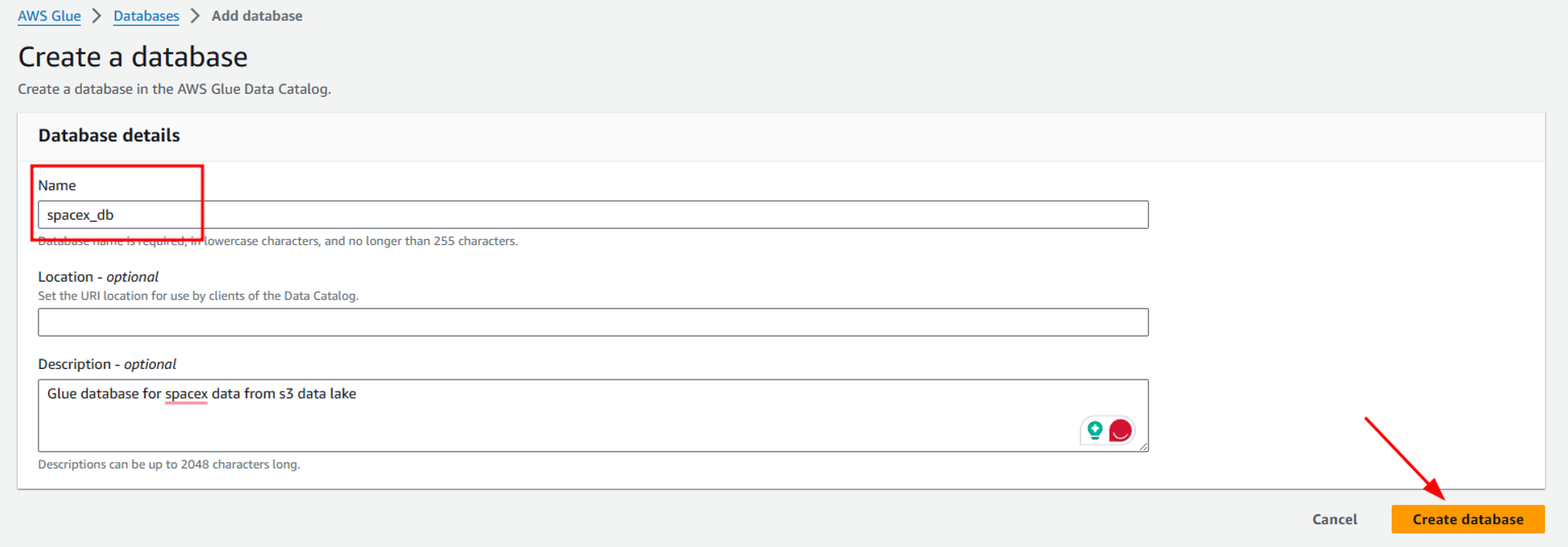
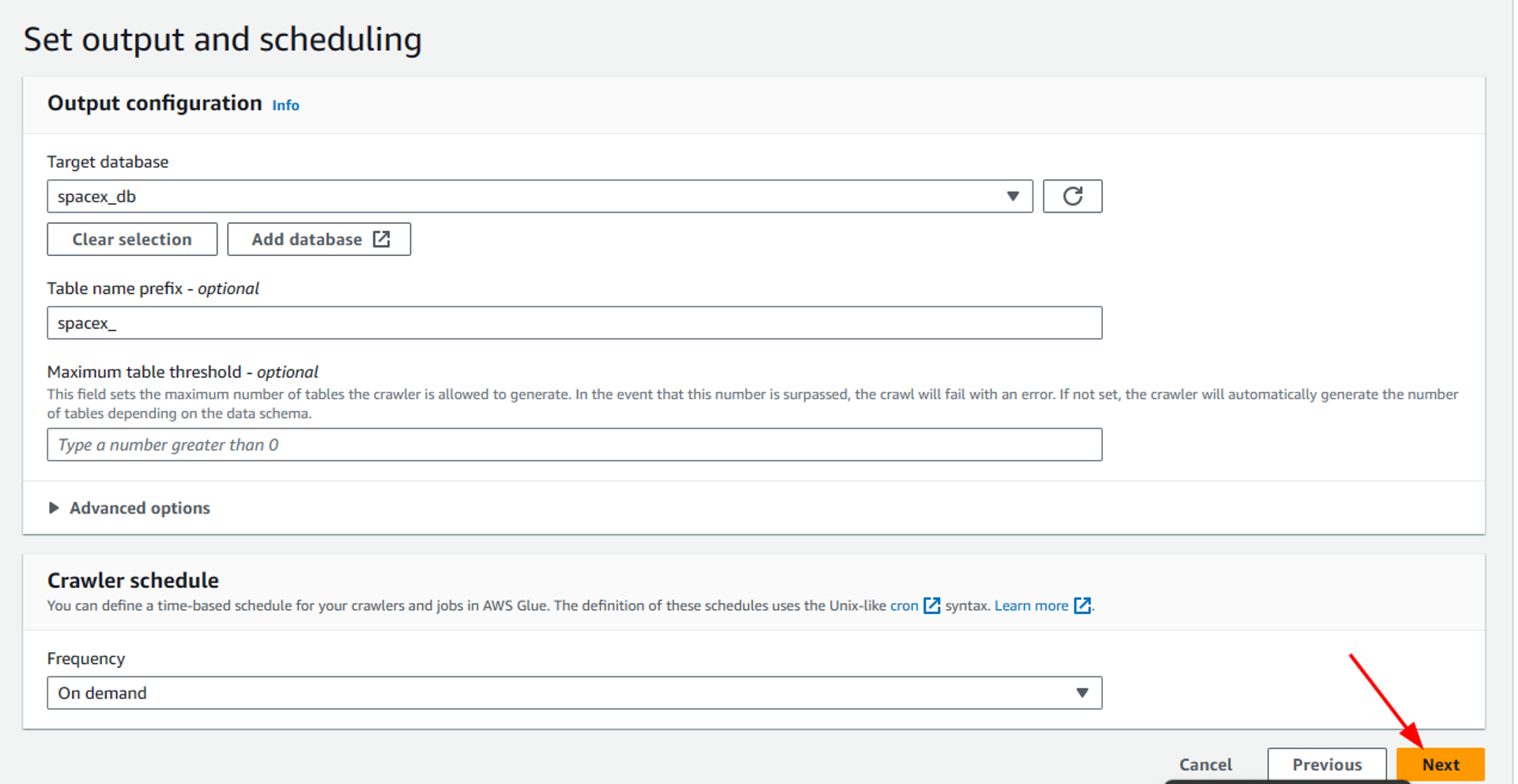
On the new page, we have to configure output for data and scheduling. Here we define a glue database as our target destination. For this, we will first add a new database by clicking on “Add database” and then provide a suitable name for the database i-e “spacex_db” in my case.

Once created return to the previous page where if we refresh the options, we can see our newly created database. Also, we can optionally configure a table prefix for the metadata tables created inside the glue database. Also in the crawler schedule we have currently selected the “On Demand” option to run the glue crawler only when we need it manually. But according to your need, you can specify a schedule to automate the crawler runs.
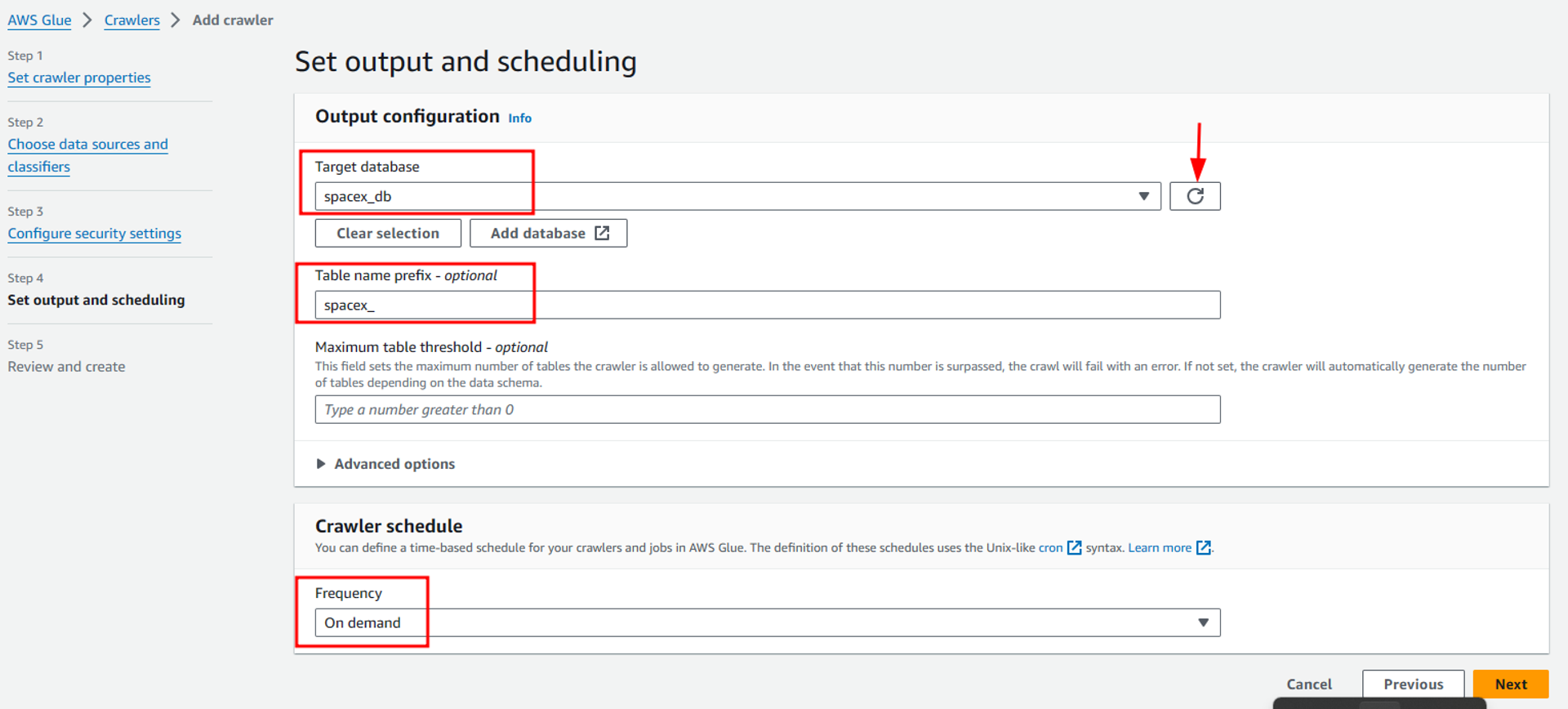
If you want you can also explore the advanced options available in Glue Crawler.
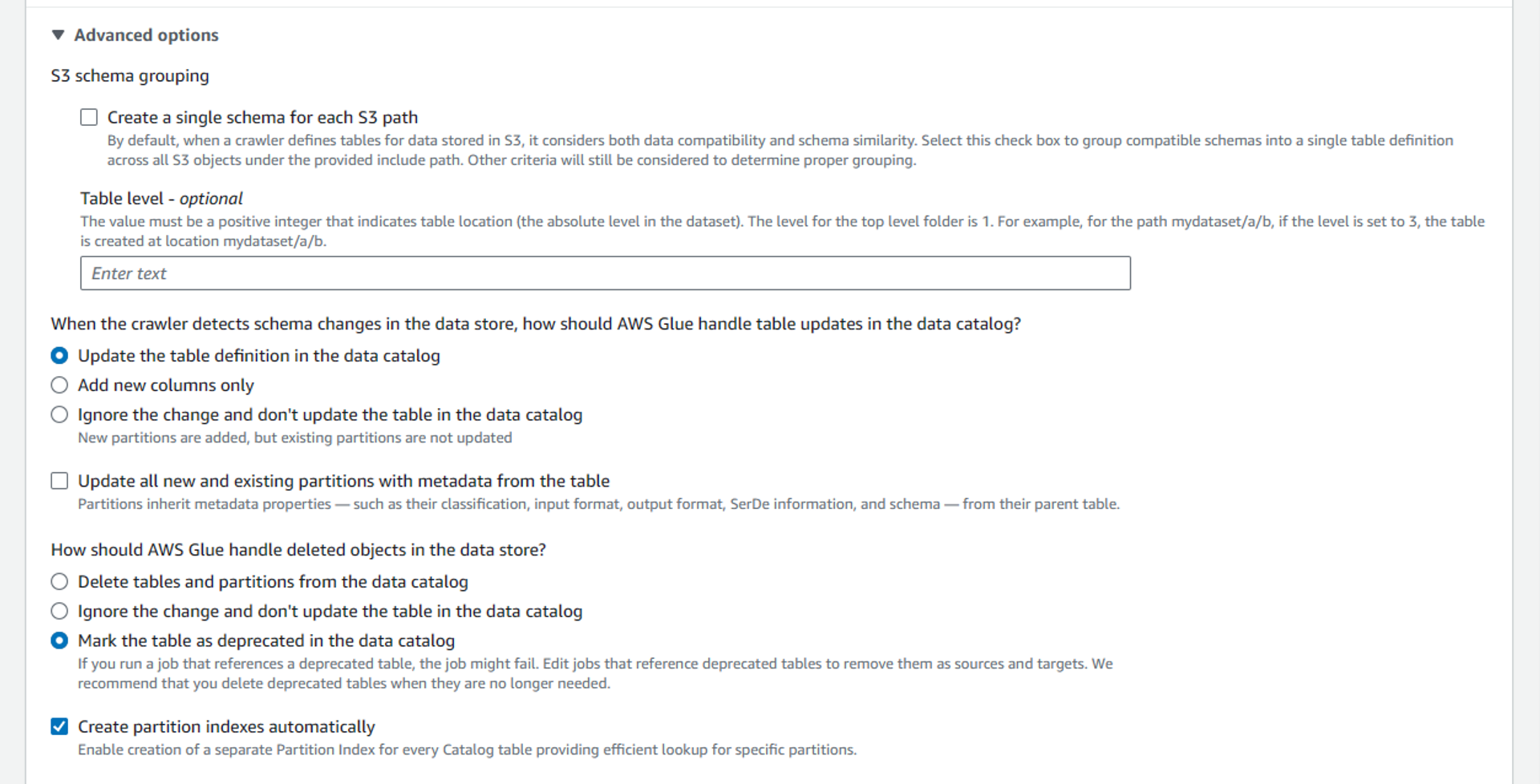
These are the scheduling options available in Glue Crawler.
Once done, we will click next.
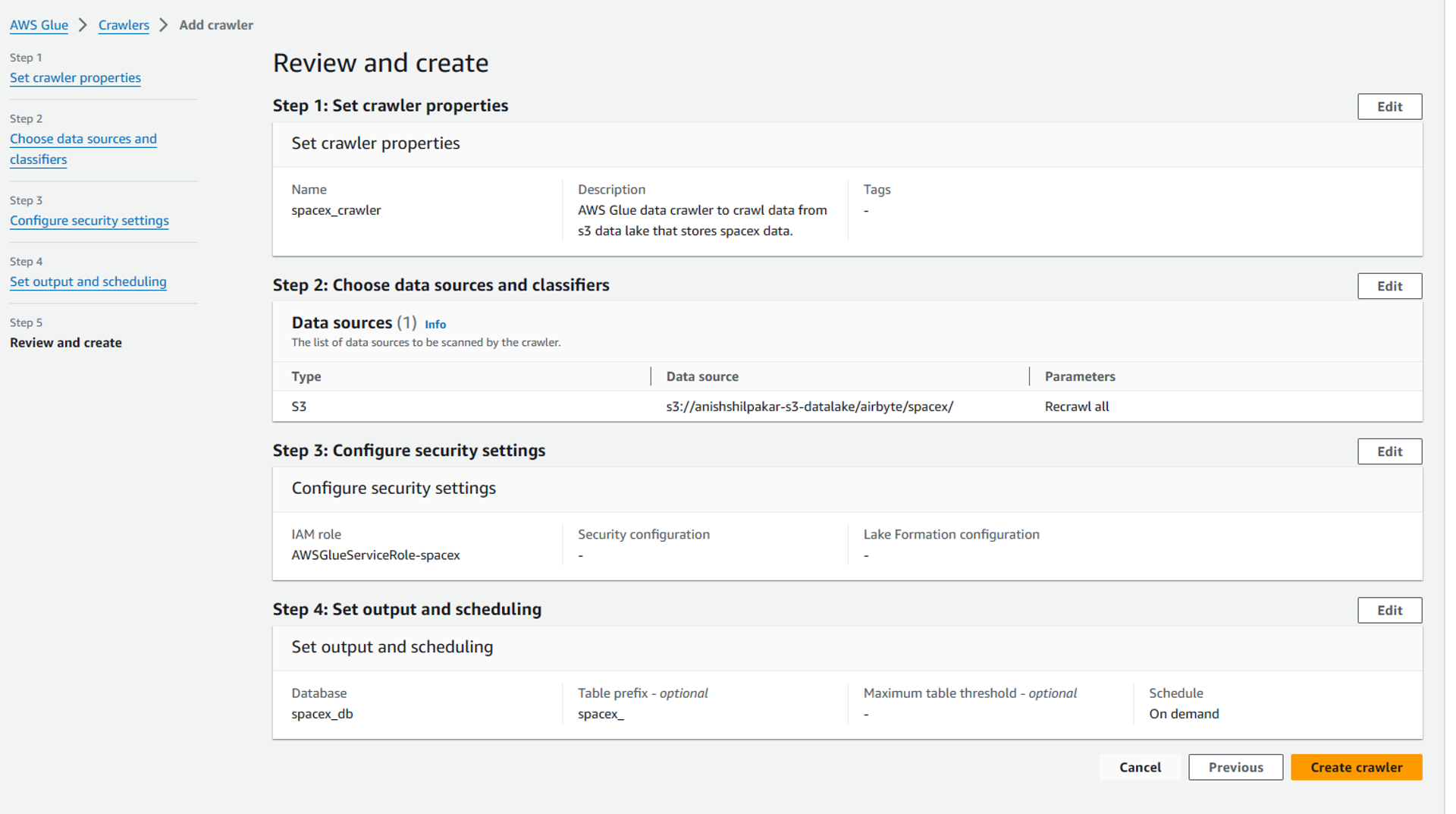
Finally, we review all the properties and options that we have configured for the AWS Glue data crawler and click on Create to create the glue data crawler. You can now see your crawler in the list of available crawlers.
Now wait till the status of the glue crawler becomes ready. Once ready click on run crawler and this will start the metadata ingestion and data cataloging process in AWS Glue.
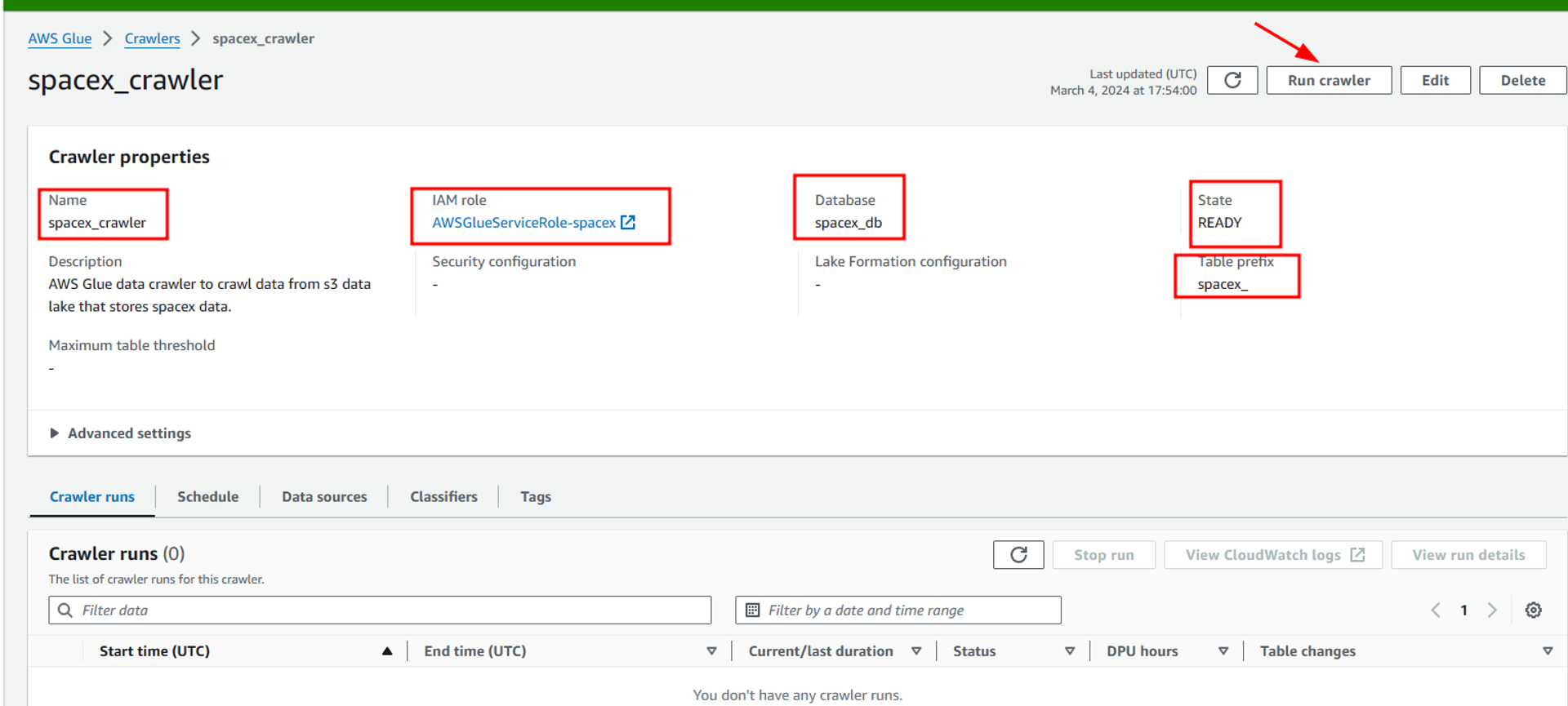
The status of the crawler changes to running which means that the crawler is now ingesting the data from the data lake and storing it inside the metadata tables in the glue database. This process takes some time and depends on the amount of data it needs to ingest from the data lake.
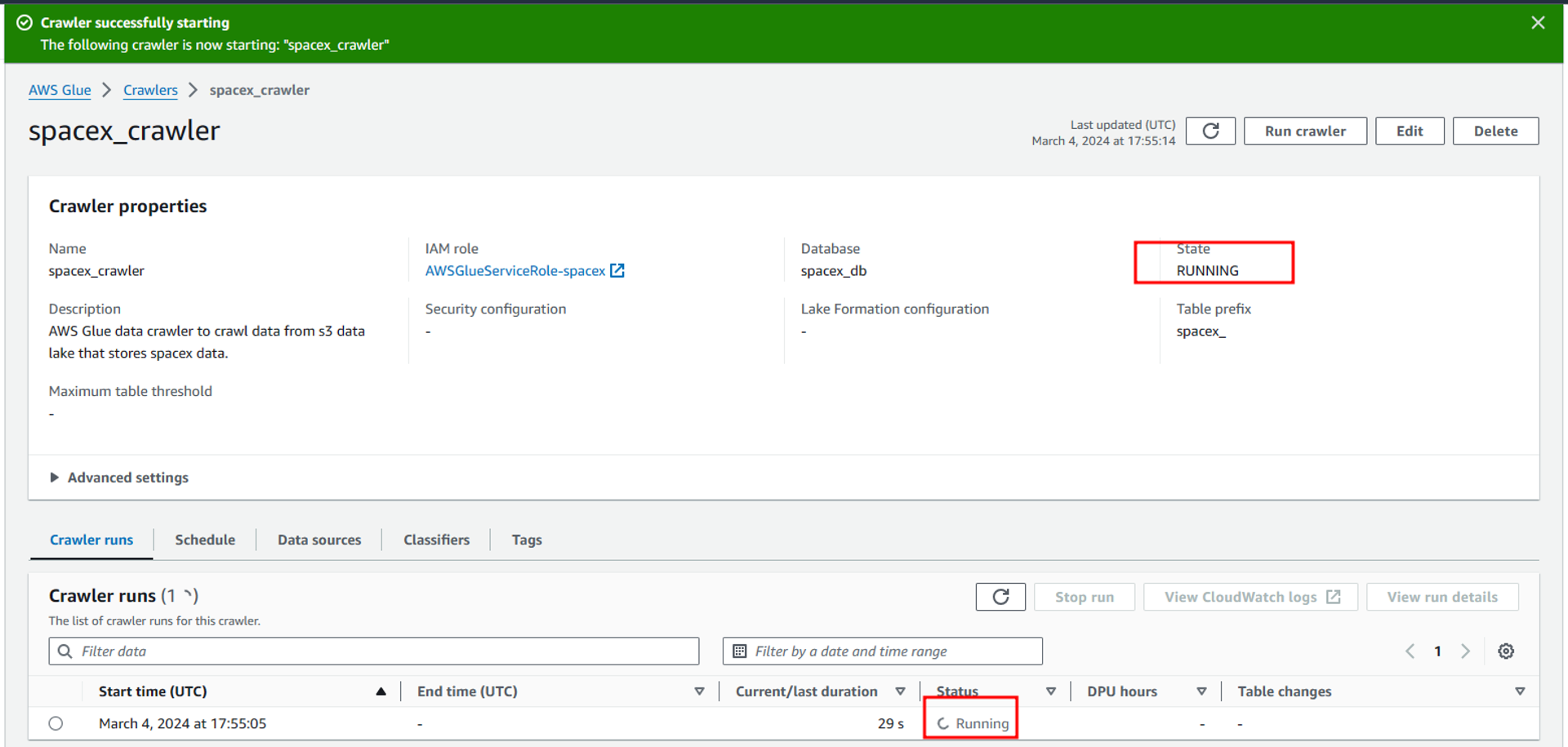
When the crawler run completes successfully, you can see the status of completed in the crawler runs tab. Also, the status of the crawler changes back to ready.
Now navigate to the AWS Glue databases page by clicking on the databases option on the right side. Here select the spacex_db
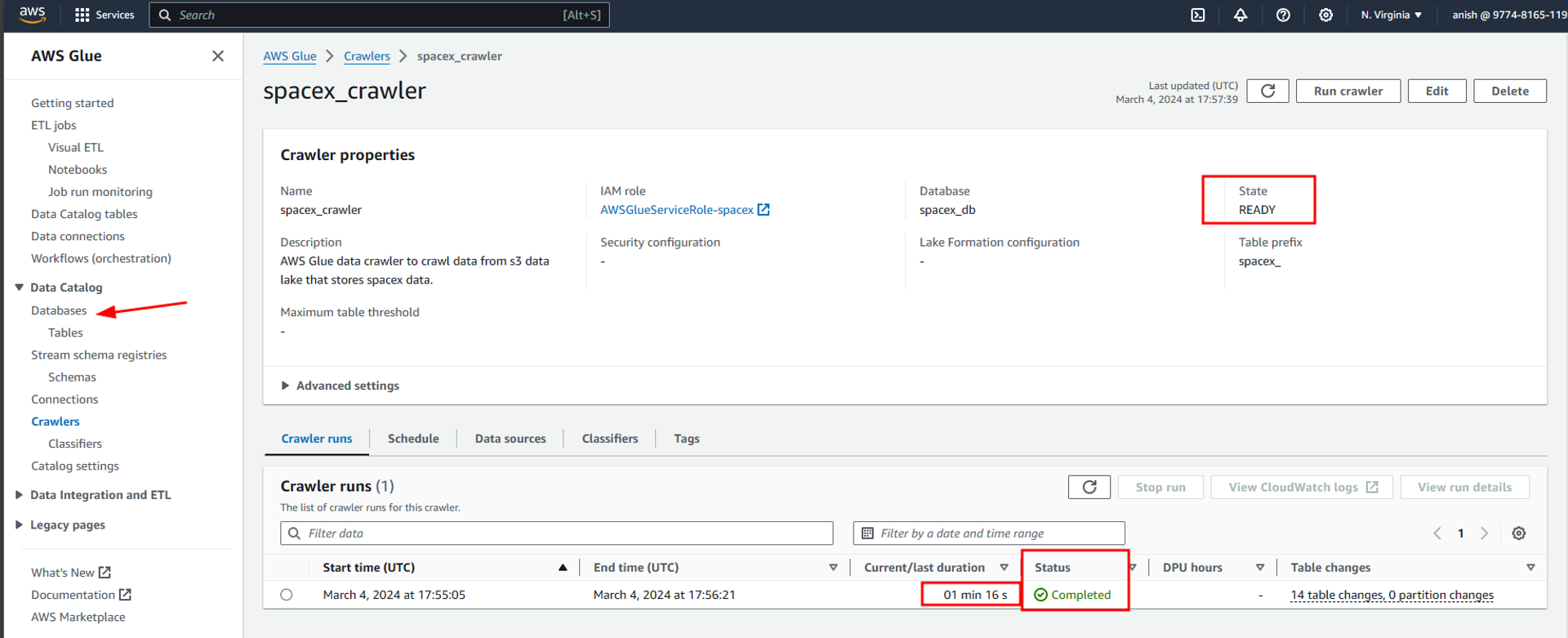
Inside SpaceX-db we can see the list of all the tables that were created after ingesting data from data lake using the glue crawler. Here we can see the names of tables, the database they belong to, their location in the s3 data lake, and the type of file that contains the original data.
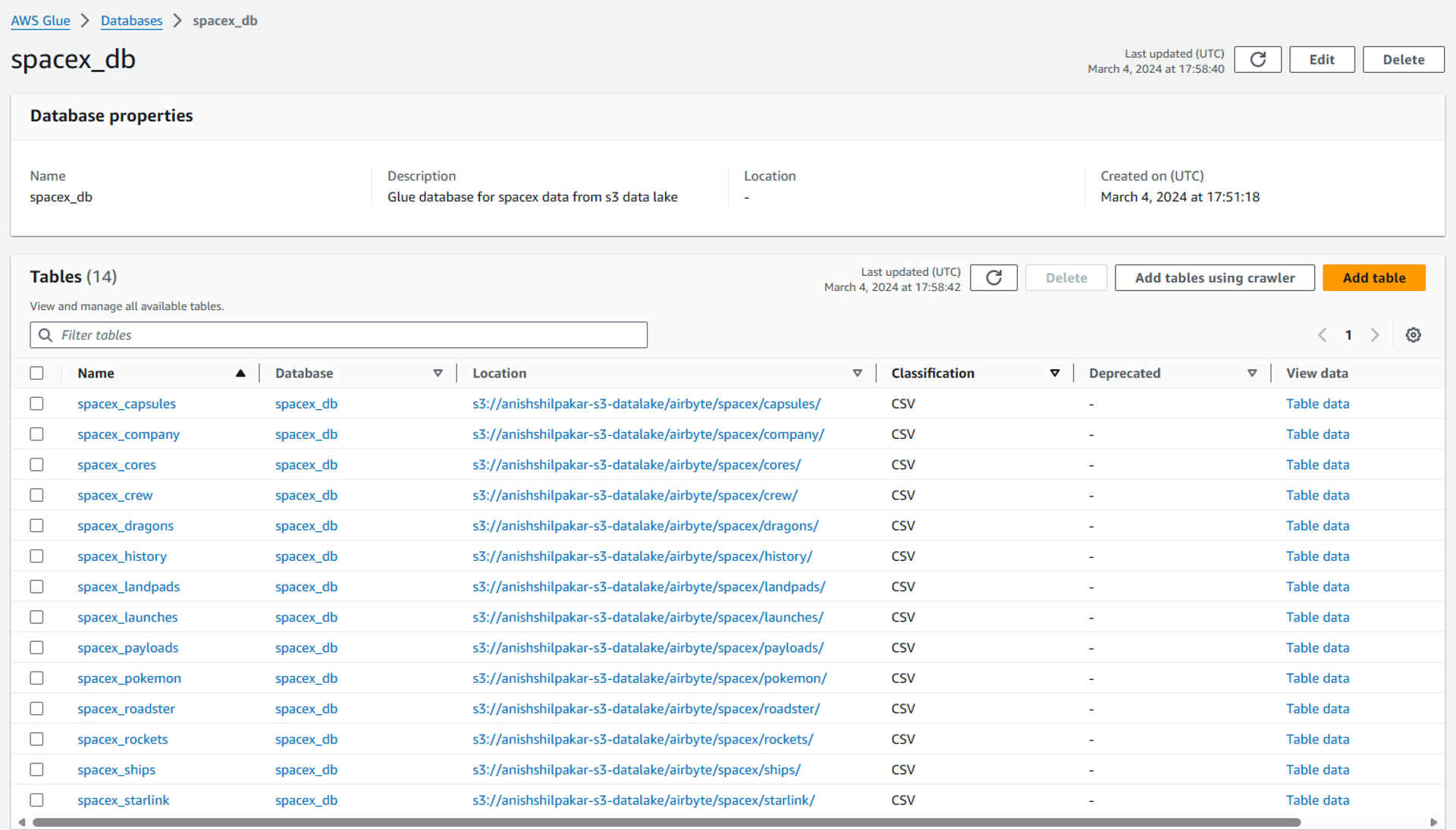
We can also view the list of metadata tables and inspect their details by navigating to the tables tab in the right-hand menu.
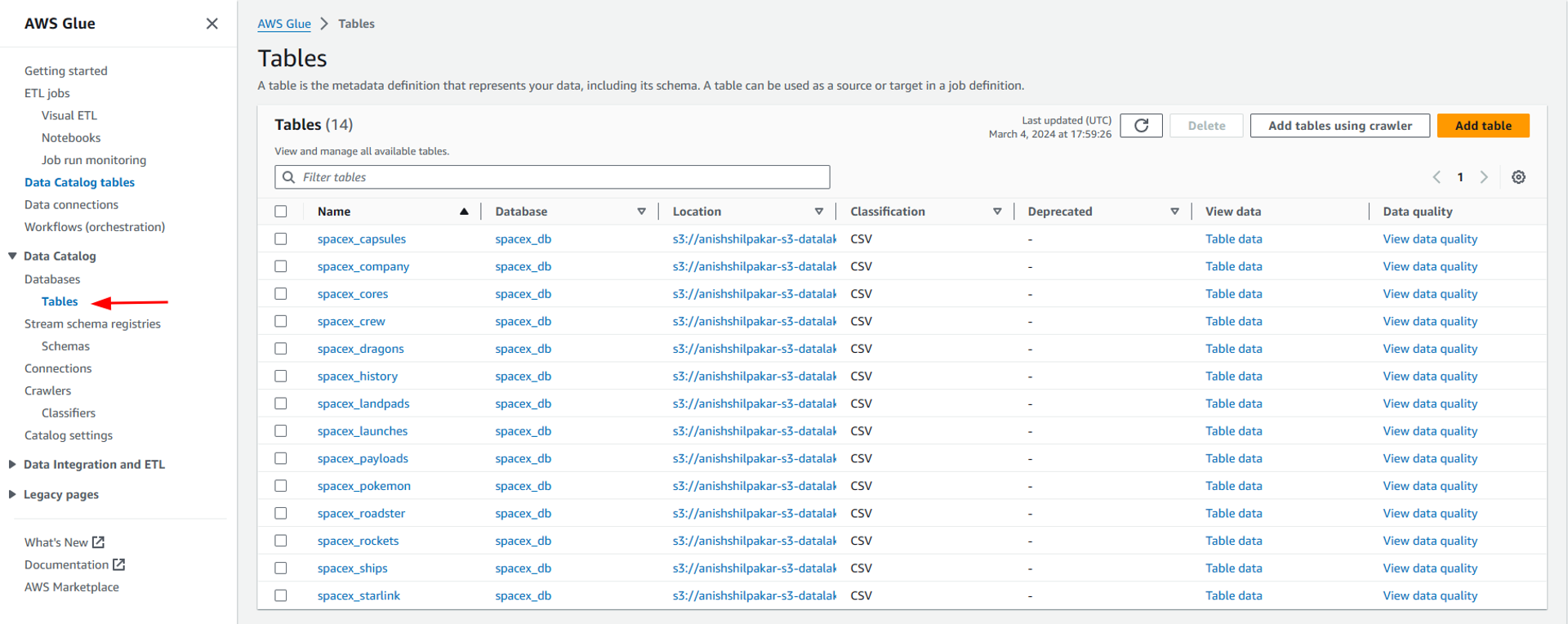
The successful creation of metadata tables inside the Glue database indicates the successful creation of the AWS Glue data catalog which contains data from our S3 data lake. Now we can use AWS Athena on this glue data catalog to analyze the data stored in our data lake easily.
Analyzing glue tables using Amazon Athena
For this firstly navigate to the AWS management console and search for Athena, then click on it to open Athena’s console.
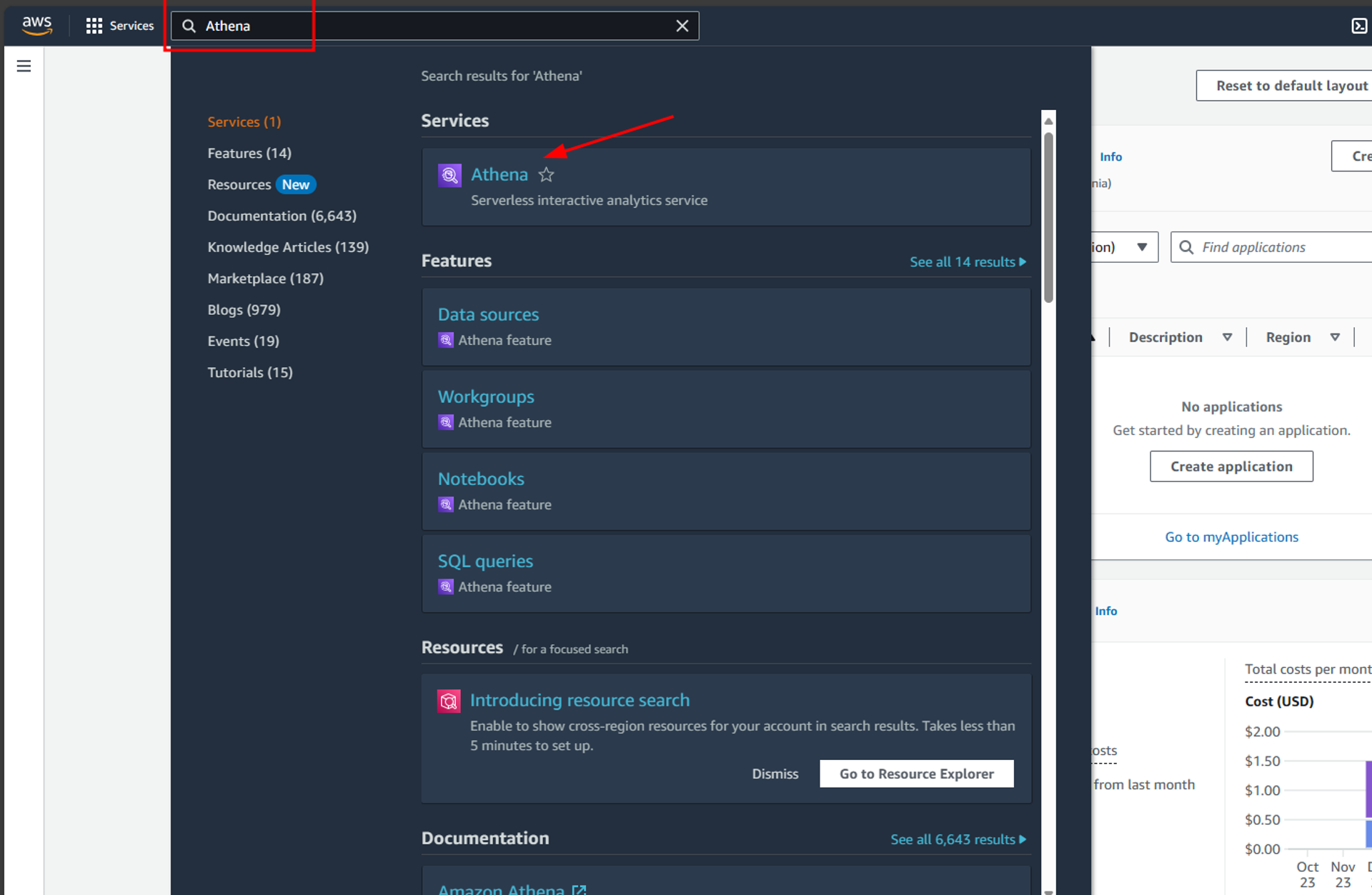
In Athena’s UI click on launch query editor to open the Athena query editor. We can use the query editor to query the tables of the Glue database and perform different analyses.
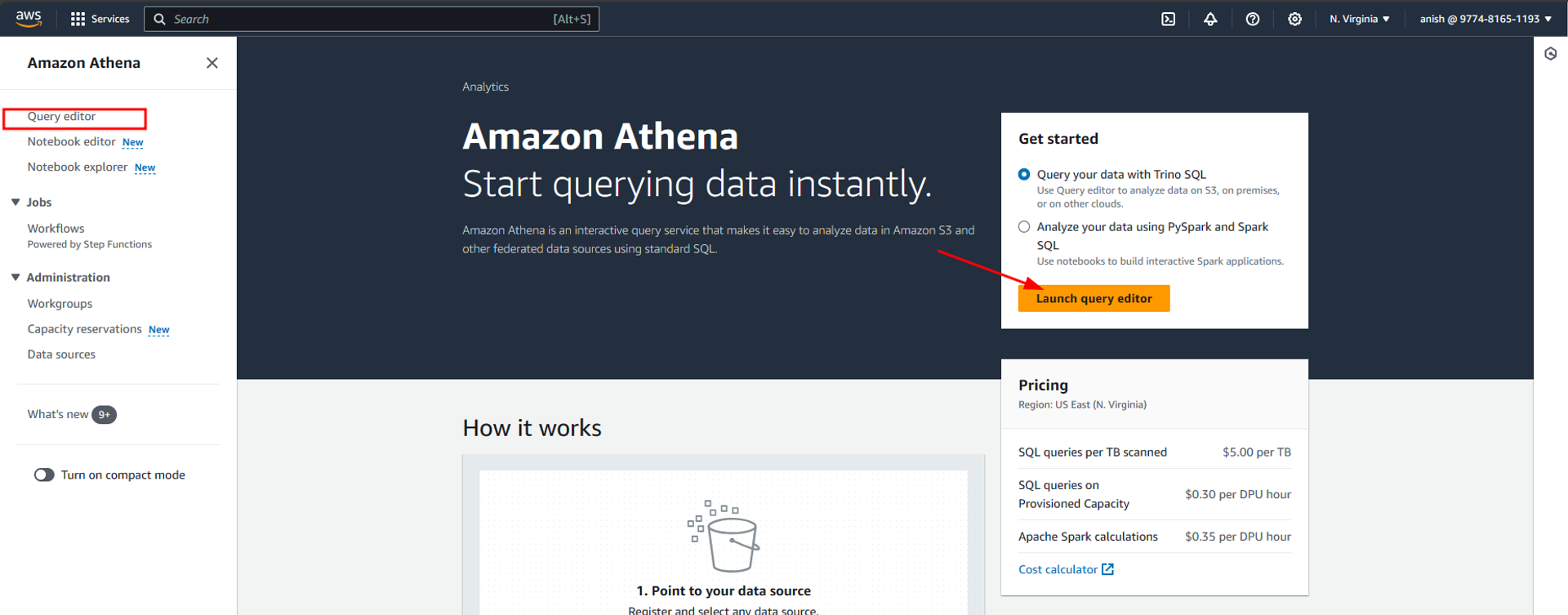
Here in the query editor, we select the data source as the glue data catalog we just created. Then we can select spacex_db in databases. This will then show the list of all the tables and views available inside spacex_db. We can now write queries in the right-hand pane of the query editor. Below I have shown a simple example where I have written a select query to query the data stored in one of the tables. Once we click on Run, we can view the results of the query below, along with the time it takes to execute the query and the total data scanned by the query.
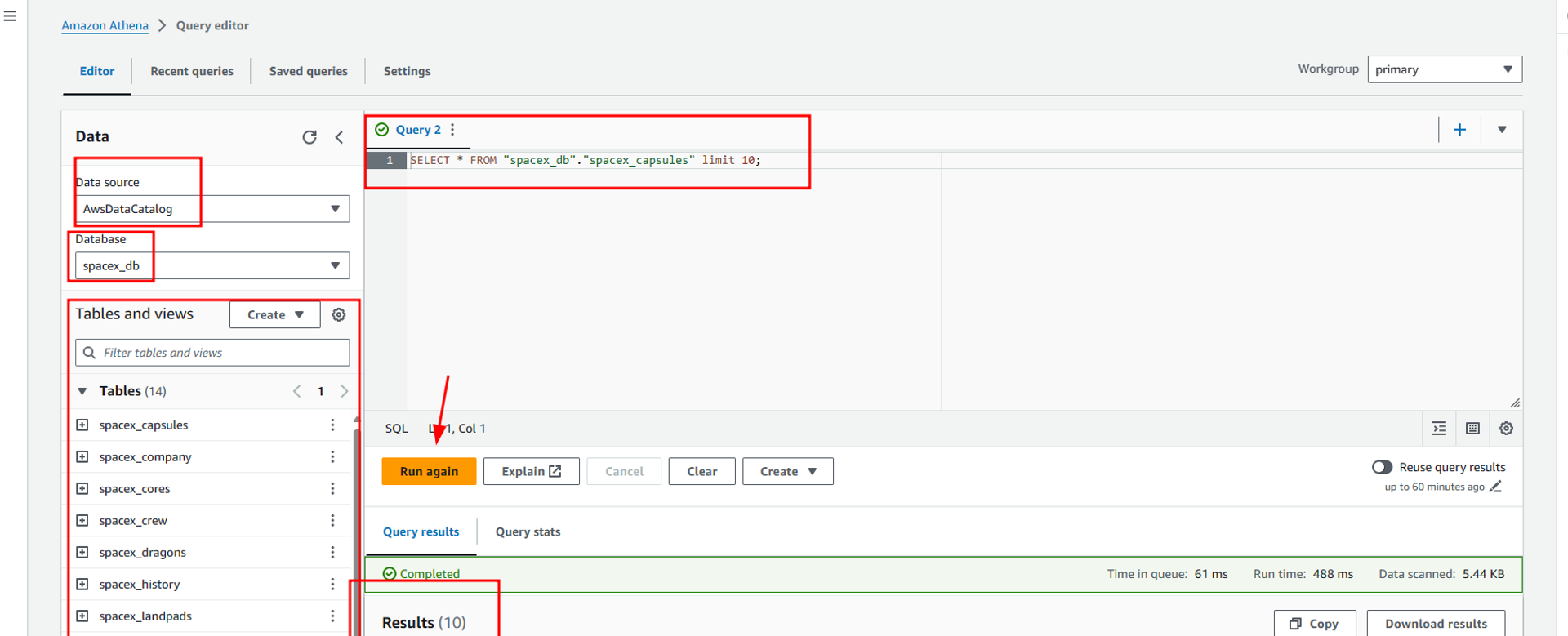
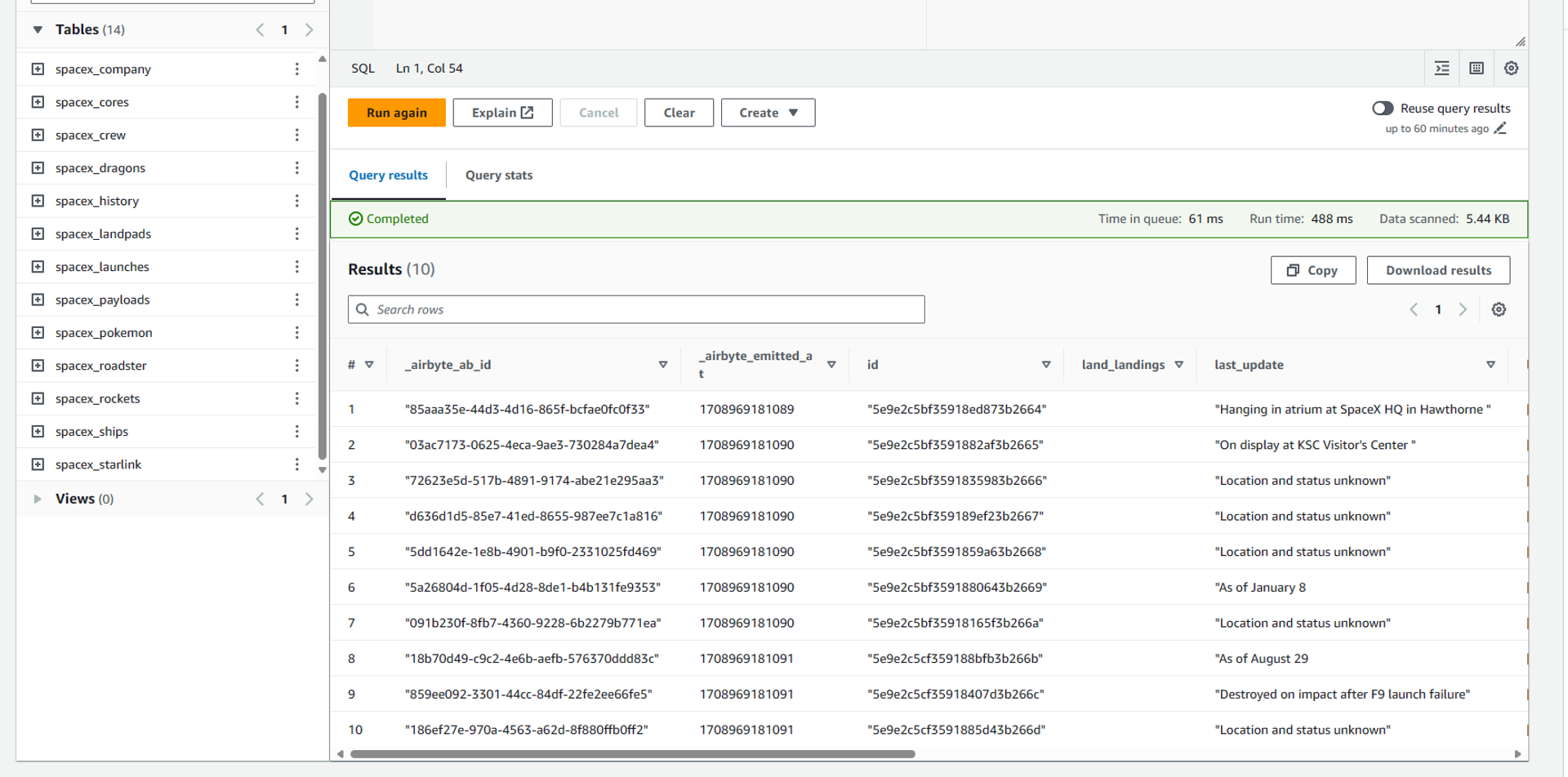
Then in this Athena query editor, we can perform different queries for data analysis, here are some of the examples.
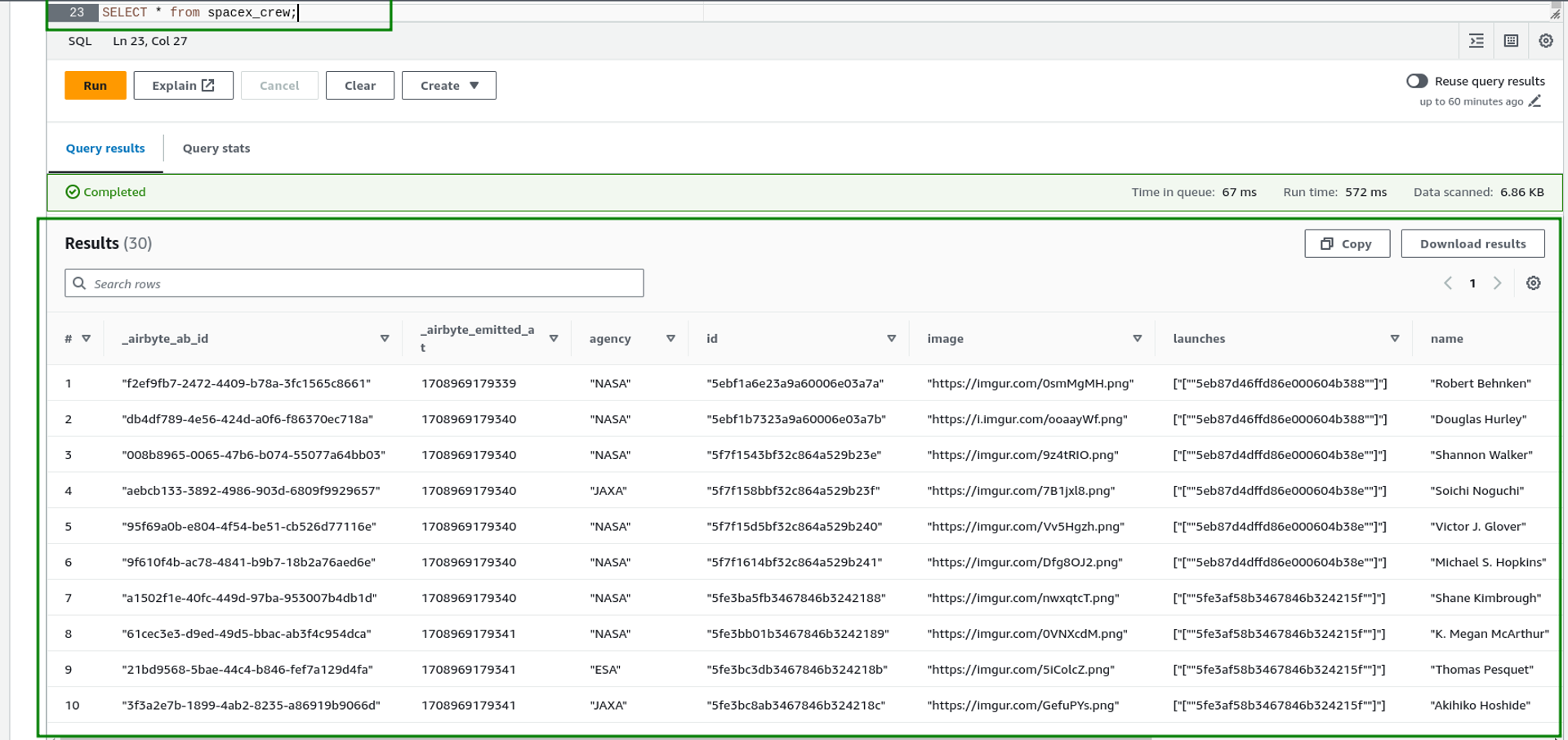
- Select all data from the spacex_crew table
SELECT * from spacex_crew;
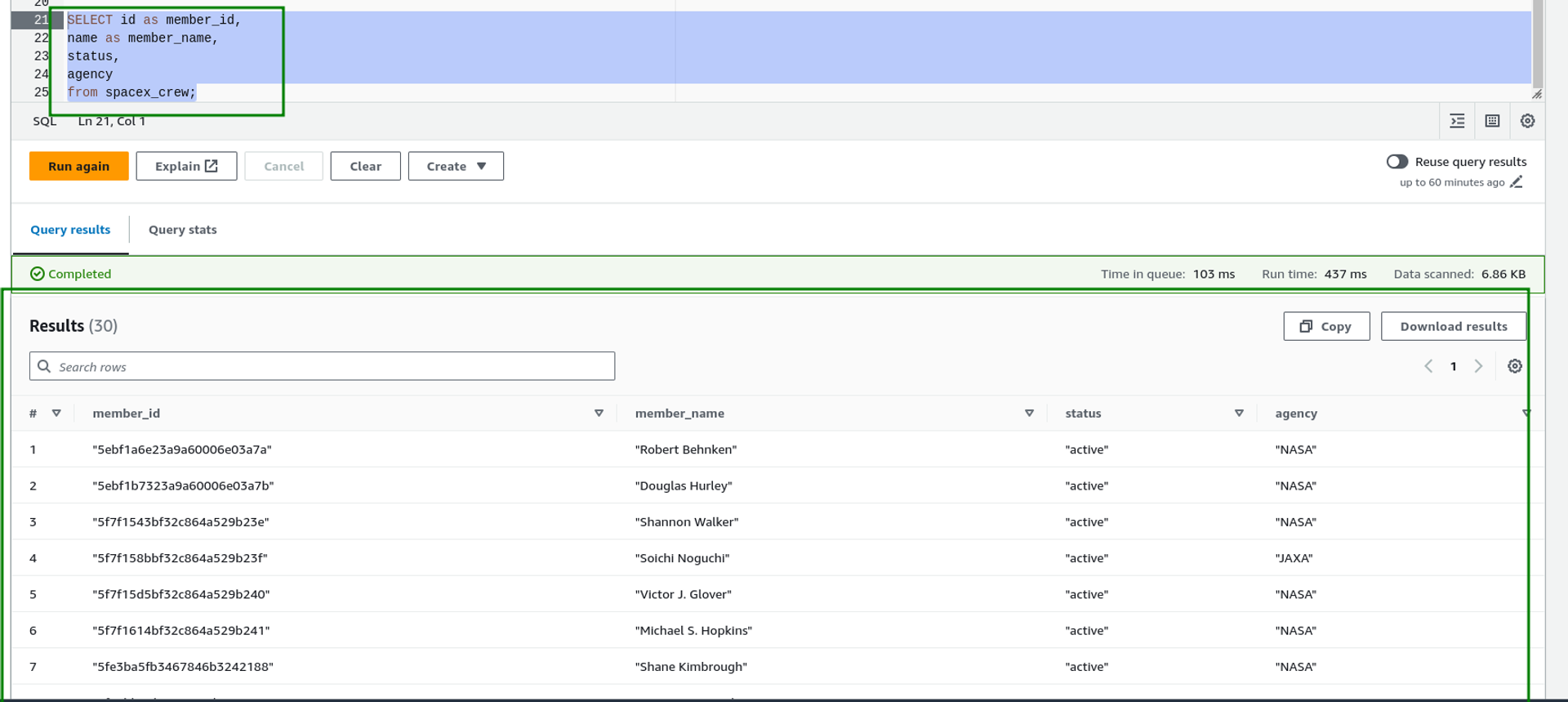
- Select specific columns from the spacex_crew table
SELECT id as member_id,
name as member_name,
status,
agency
from spacex_crew
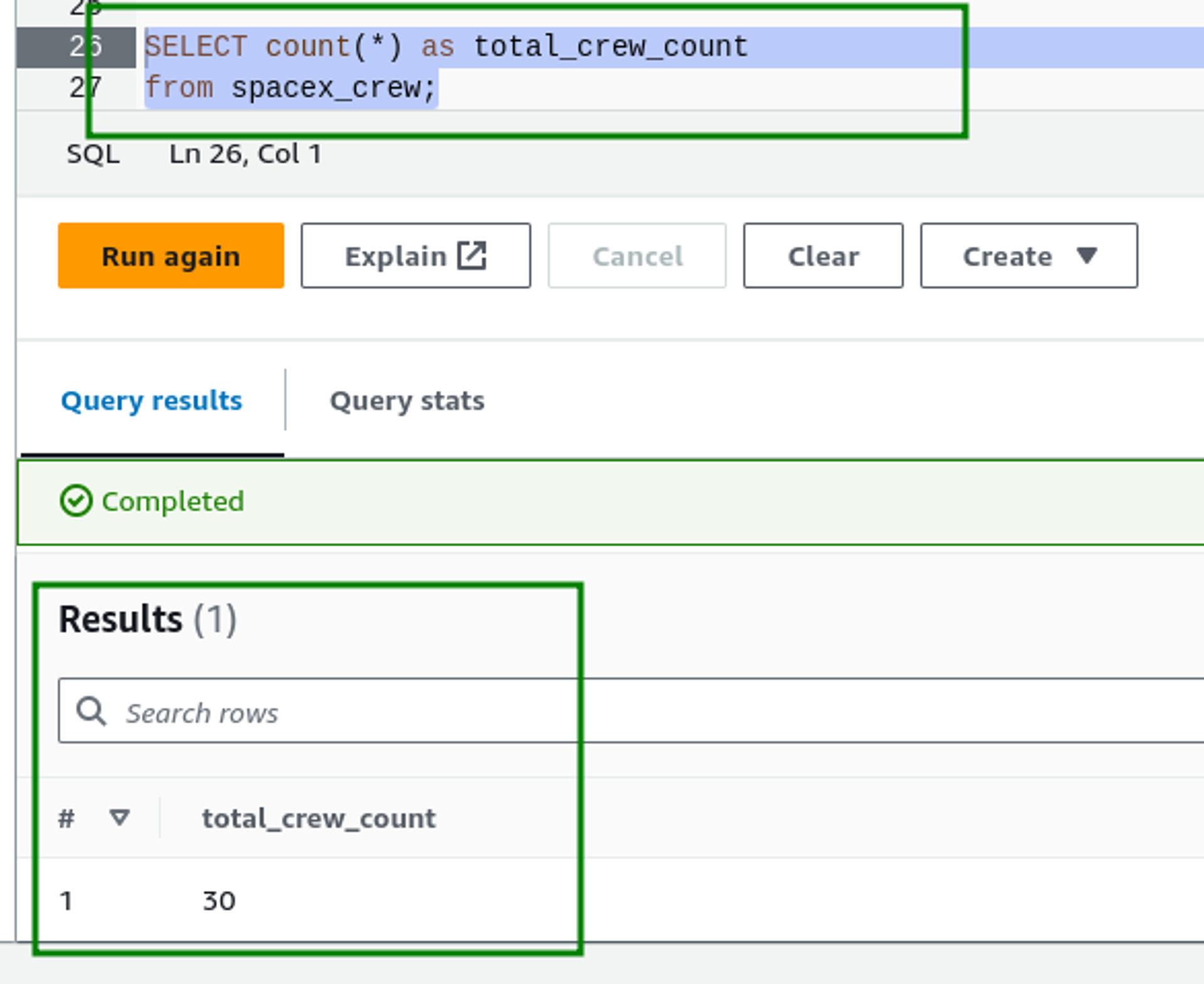
- Finding the count of total crew members using the COUNT() aggregation function
SELECT count(*) as total_crew_count
from spacex_crew;
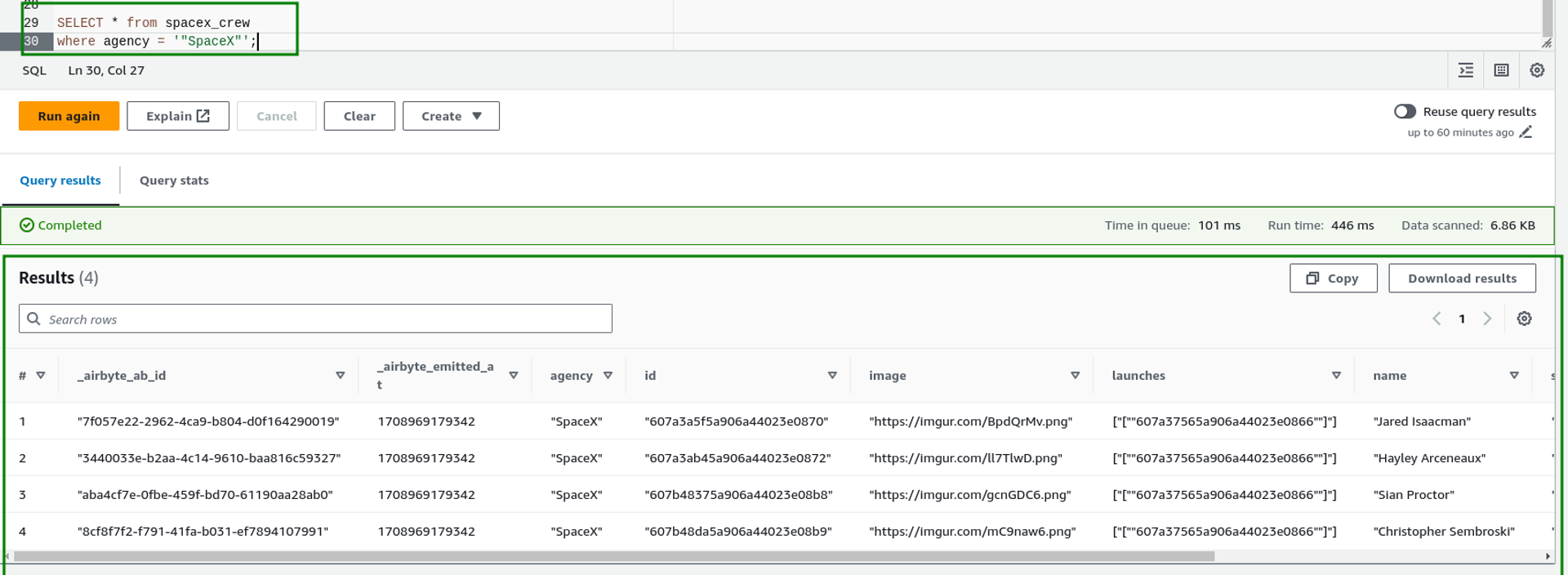
- Filtering data to get details of crew members belonging to “SpaceX” agency
SELECT * from spacex_crew
where agency = '"SpaceX"';
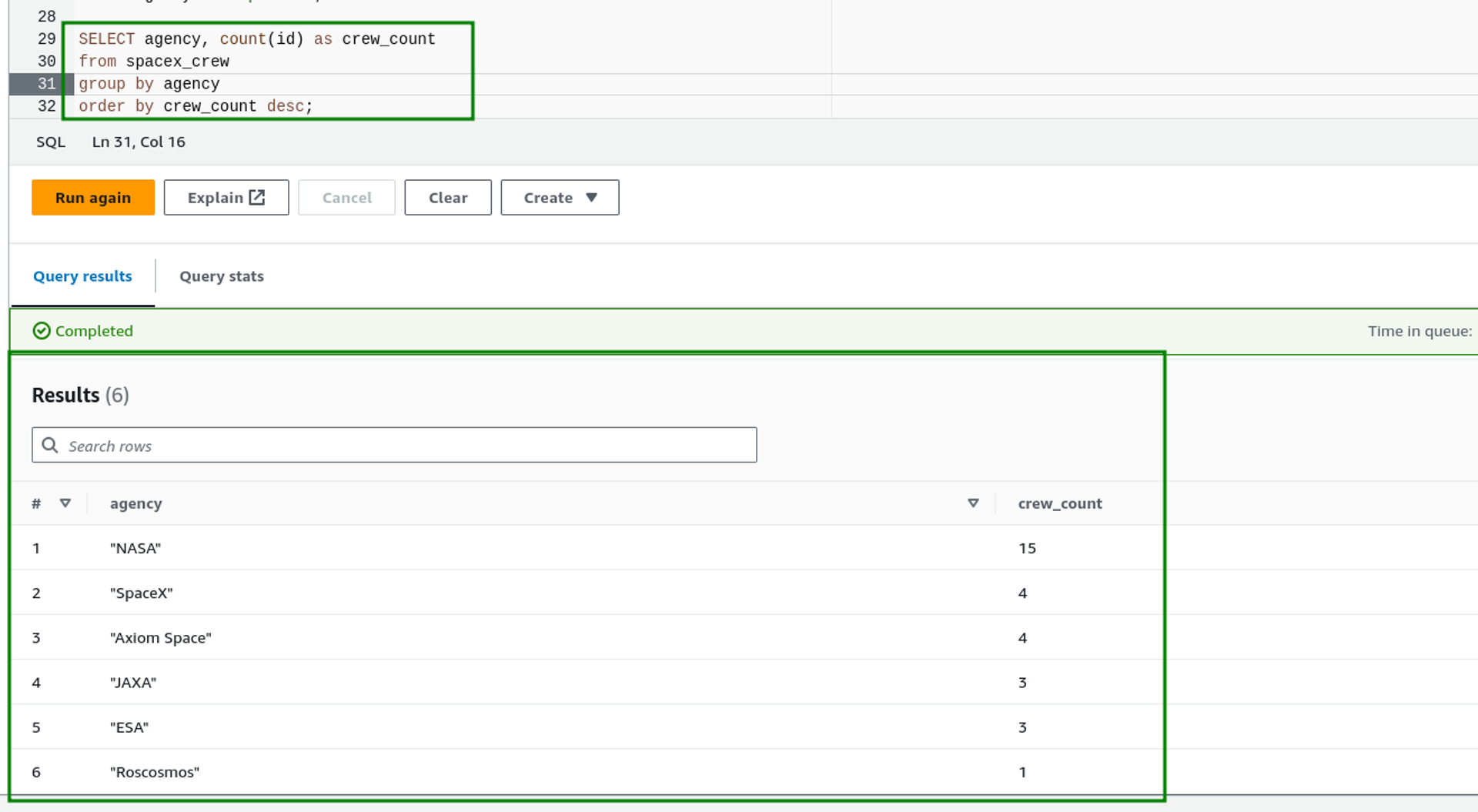
- Aggregating the data based on agency to find the number of members belonging to each agency.
SELECT agency, count(id) as crew_count
from spacex_crew
group by agency
order by crew_count desc;
Hence in this way, we can run different SQL queries to analyze the data from the data lake in AWS Athena. Here I have only shown a few examples of queries, you can try to run more complex queries using joins, subqueries, etc. based on your data model. Also, if we want to do more complex data transformations, cleaning, and analysis in our data we will use spark notebooks from Glue ETL to process the data.
Conclusion
In conclusion, the combination of AWS Glue and AWS Athena offers a powerful solution for data analytics on the AWS platform. By utilizing AWS Glue's data crawler to ingest data from the s3 data lake, creating a Glue data catalog with databases and tables, and analyzing the data in Glue tables using SQL queries in AWS Athena, valuable insights can be effectively extracted the data, as we have done in our project so far. These tools streamline the process of data discovery, preparation, and integration, making it easier for businesses to gain a competitive edge by making data-driven decisions, improving operational efficiency, and identifying new business opportunities in today's data-driven world.
Epilogue
Hence, simple data analytics was done over the data we loaded in the S3 data lake using AWS Glue and AWS Athena. In the next part of this project, I will be cleaning and transforming the data using spark notebooks in AWS Glue and will finally load the transformed data into AWS Redshift, which will be the final data warehouse for storing the processed data.
Previous Blog Link: Unlock Big Data Insights: A Beginner's Guide to ELT with Airbyte & S3 (anish-shilpakar.com.np)
https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
https://docs.aws.amazon.com/athena/latest/ug/what-is.html