A Beginner’s Guide to Data Engineering: Unlocking the Power of Data with AWS

I am a computer engineering undergraduate highly interested in Data engineering, Artificial intelligence, Machine Learning and Natural language processing. I like exploring and learning new technologies and I will be writing various blogs here during my learning journey
Introduction
Hello There 👋🏻. Hope you all are doing well. In my previous blog, I discussed the significance of data engineering for data-driven organizations and highlighted several essential components of data engineering. And, In this blog post, I will delve into some of the most commonly used AWS services for data engineering and provide examples of how we can use these services to construct modern data pipelines. Data engineering involves the use of specialized tools and technologies to construct robust, scalable, and efficient data pipelines capable of handling vast amounts of data from various sources. With the emergence of cloud computing, data engineering has also shifted to the cloud, where several cloud service providers like AWS, Google Cloud Platform, Microsoft Azure, IBM, etc., offer a range of tools and services to build efficient data infrastructures and handle large volumes of data. Among them, AWS (Amazon Web Services) is the leading cloud service provider that offers a wide range of data services to build various data engineering solutions and simplify the process of creating scalable, robust, and secure data pipelines.
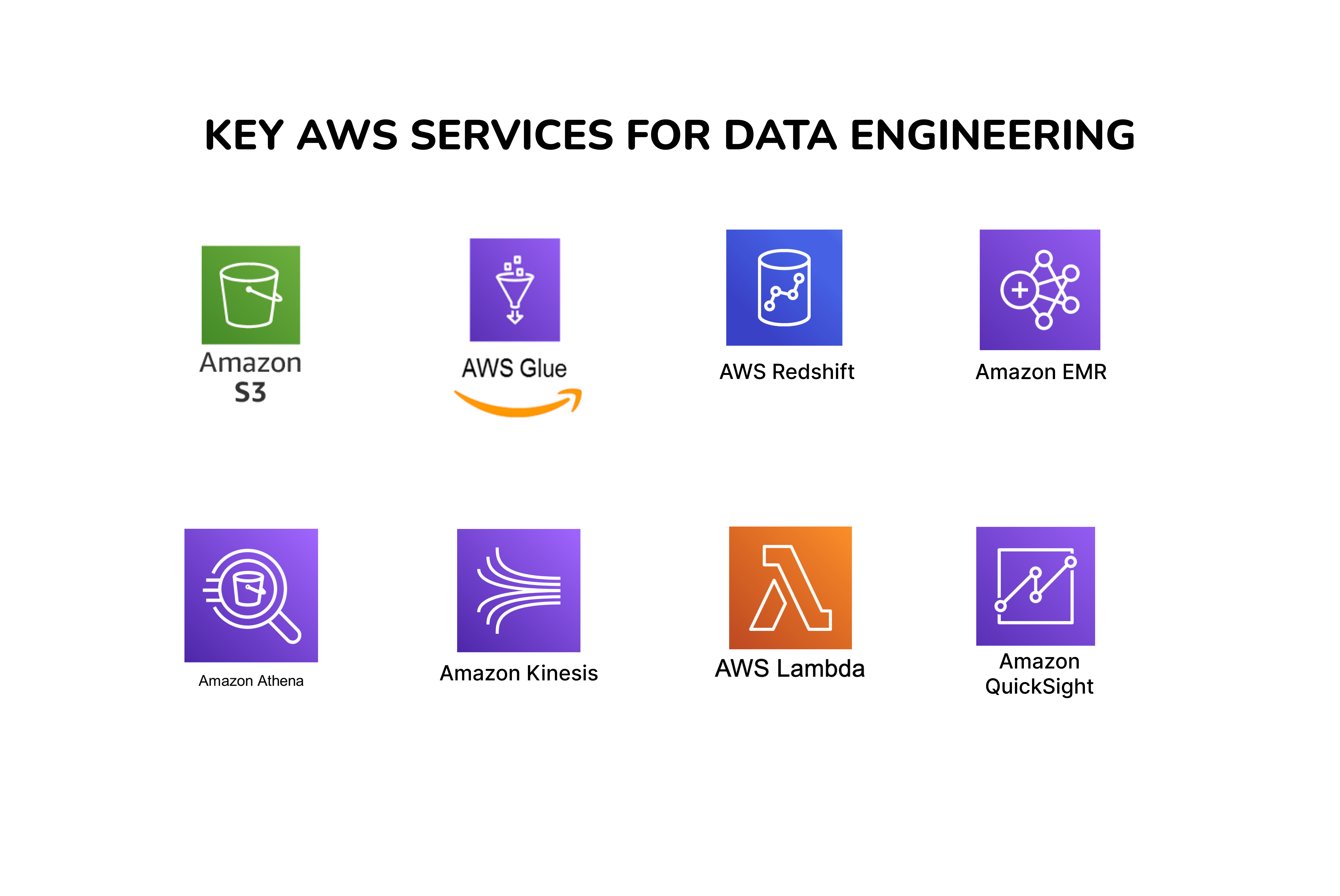
Key AWS services for Data Engineering
Amazon S3
AWS Glue
Amazon Redshift
Amazon EMR
Amazon Athena
Amazon Kinesis
AWS Lambda
Amazon QuickSight
1. Amazon S3 (Simple Storage Service)
Amazon S3 is a widely used storage service provided by AWS that is commonly utilized in data engineering tasks. S3 offers highly scalable and durable object-based storage that can store a practically unlimited amount of data. Data in S3 is stored as objects, which are files that consist of a key, version ID, value, metadata, sub-resources, and access control information. These objects are stored in buckets, and their size can range from a minimum of 0 bytes to a maximum of 5 terabytes. S3 has virtually unlimited storage capacity, making it an ideal solution for storing big data. In data engineering, S3 serves as a data lake that stores structured, semi-structured, and unstructured data in its native format, enabling easy querying and analysis using other AWS data services.
Example: Let's say you are a media company that wants to store and process large volumes of video files. You can use S3 to store the video files and use S3's versioning and lifecycle policies to manage the files. You can also use S3's access control options to restrict access to the files based on user roles and permissions. Also, this data can later be ingested by an ETL pipeline and stored in a data warehouse for further analysis.
2. AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service offered by AWS that simplifies the development of scalable, efficient, and cost-effective ETL pipelines. It enables the easy movement of data between data sources and supports various data formats such as CSV, JSON, and Parquet. Glue's serverless architecture automatically scales to handle large data volumes and simplifies ETL pipeline development. With AWS Glue, data engineers can easily discover, prepare, move, and integrate data from multiple sources, supporting workloads like analytics, machine learning, and application development. AWS Glue provides several services for data engineering, including crawlers that automatically discover and infer data schema from data stores, jobs that run ETL scripts for transforming data, data catalogs that store metadata information about data sources, tables, and schemas, and workflows that orchestrate complex ETL workflows. AWS Glue supports a range of data engineering tasks, making it an essential component for building data pipelines in the AWS ecosystem.
Example: Let's say you have a set of CSV files stored in S3 that you want to analyze using Athena. You can use a crawler to automatically detect the schema of the CSV files, create a table in the Glue Data Catalog, and make the data available for querying in Athena. You can also Glue jobs to transform the data from one format to another.
3. Amazon Redshift
Amazon Redshift is a fully managed data warehousing service offered by AWS that enables the analysis of large amounts of data using SQL queries and business intelligence tools. Redshift can handle petabyte-scale storage and provides fast query performance through columnar storage and massively parallel processing. In data engineering, Redshift is commonly used as a destination data store for ETL pipelines, and the data stored in Redshift typically consists of historical data that is analyzed to generate business insights to support decision-making. Redshift can also be used to transform data using SQL, create views and materialized views, and join multiple tables for complex analysis. Data in Redshift can be stored using star schema or snowflake schema.
Example: Let's say you have a retail company that sells products online and in physical stores. You can use Redshift to store transactional data from online sales, point-of-sale systems, and customer data from a CRM system. You can create a star schema in Redshift that allows you to analyze sales data by product, customer, and region, and to identify trends and opportunities.
4. Amazon EMR (Elastic MapReduce)
Amazon EMR is a fully managed big data platform provided by AWS. It enables running big data frameworks like Apache Hadoop, Apache Spark, and Presto to process and analyze large amounts of data in parallel across a cluster of EC2 instances. EMR allows for faster and more cost-effective petabyte-scale data processing and interactive analytics. In data engineering, EMR is used for big data analytics, building scalable data pipelines, and processing real-time data streams.
Example: Let's say you are an e-commerce company that wants to analyze customer transaction data. You can use EMR to run a Spark cluster that processes the data stored in S3 and use Spark's machine learning and graph processing libraries to generate insights on customer behavior and product recommendations.
5. Amazon Athena
Amazon Athena is a serverless, interactive query service offered by AWS that provides a simple and flexible way to analyze large volumes of data stored in Amazon S3 using standard SQL. Athena enables users to query data in S3 without the need for infrastructure setup or data loading, which makes it an excellent tool for ad-hoc querying and analysis. Built on open-source frameworks, Athena supports open-table and file formats and provides a flexible environment for querying and analyzing data. In data engineering, Athena is commonly used for data analysis and exploration, as well as for creating ad-hoc reports and dashboards.
Example: Let's say you have a set of log files stored in S3 that you want to analyze using SQL. You can create a Glue table that maps to the log file structure, and then run ad-hoc queries to analyze the log data using Athena. You can use SQL functions to filter and aggregate data, and you can save the results to a new table in S3 or Redshift.
6. Amazon Kinesis
Amazon Kinesis is a real-time streaming data service offered by AWS that enables the ingestion and processing of large volumes of real-time streaming data. This type of data includes continuous data generated in real-time, such as social media data, IoT sensor data, and web server logs. Amazon Kinesis provides a fully managed service that can cost-effectively process and analyze streaming data at any scale. It is widely used to create real-time applications, video analytics applications, and analyze IoT device data. Amazon Kinesis offers services like Kinesis Data Streams, which captures, processes, and stores streaming data; Kinesis Data Firehose, an ETL service that reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services; Kinesis Data Analytics, which easily transforms and analyzes streaming data in real-time, and Kinesis Video Streams, which easily and securely streams video from connected devices to AWS. In data engineering, Kinesis is used for ingesting and processing streaming data and for real-time analytics.
Example: Let's say you are a retailer who wants to analyze customer behavior in real time. You can use Kinesis Data Streams to ingest and process customer clickstream data and use Kinesis Data Analytics to perform real-time analysis of the data. You can analyze customer behavior, such as page views, clicks, and session length, and use the results to optimize your website, improve customer experience, and increase sales.
7. AWS Lambda
AWS Lambda is a fully managed, serverless computing service provided by AWS that allows developers to run their code without the need for servers or infrastructure management. It is event-driven, which means it can automatically execute code in response to a specific event or trigger, such as changes in data, file uploads, or user actions. Lambda can be used to create scalable and cost-effective applications and backends, process data at scale, automate workflows, and perform machine learning tasks. In data engineering, Lambda can be used for real-time data processing, data integration, and triggering other AWS services such as Amazon S3 or Amazon DynamoDB. With Lambda, developers can focus on writing code and business logic, while AWS takes care of scaling, availability, and security.
Example: Let's say you are a healthcare provider who wants to integrate patient data from multiple sources, such as electronic health records and wearable devices. You can use Lambda to extract data from each source, transform the data to a common format, and synchronize the data in a data lake or data warehouse. You can write a Lambda function that triggers when new data is available in each source and performs the necessary data integration tasks.
8. Amazon QuickSight
Amazon QuickSight is a fully managed business intelligence and analytics service offered by AWS that simplifies the process of creating and sharing interactive visualizations, reports, and dashboards. With QuickSight, users can connect to various data sources including AWS data services, on-premises databases, third-party data sources, and flat files. It supports various data formats like CSV, Excel, JSON, and more. QuickSight provides a range of data visualization options such as bar charts, line charts, heat maps, and geospatial visualizations, which can be used to create compelling and interactive dashboards for data exploration and analysis. QuickSight also supports various features like ML Insights, Auto-Narratives, and themes that help to make data more accessible and easier to understand for non-technical users. In data engineering, QuickSight can be used for data exploration, data visualization, and data reporting, helping teams to gain deeper insights into their data and make better decisions.
Example: Let's say you are a retailer who wants to analyze sales data across multiple regions and product categories. You can use QuickSight to connect to your data sources and explore the data using filters and groupings. You can create visualizations such as bar charts, line charts, and pie charts to understand sales trends and patterns.
Conclusion
In conclusion, AWS provides a wide range of services for data engineering making data engineering easier, more efficient and cost-effective. Apart from the services I have mentioned in this blog, AWS also offers various other data services like Aurora, DynamoDB, DocumentDB, EFS, RDS, CloudFormation etc. By leveraging various AWS services we can build robust, scalable and efficient data pipelines to collect, store, process and analyze vast amounts of data from various sources and to generate insights that help in business decision-making. Data engineering is an ever-evolving field, and new tools and services are constantly being developed by companies like AWS that enable us to build modern data pipelines and unlock the true power of data.
Epilogue
I am a computer engineering undergraduate and am highly interested in the data and AI field. I recently started learning data engineering and am writing blogs to share my learning. This is my second blog in the data engineering series and I hope you enjoyed reading this. Next, I will be writing blogs related to some data engineering projects including AWS services, so stay tuned ✌🏻. This is the way ☄️.